文|脑极体
哪些公司在做大模型?面对这个问题,我们首先会想到大型互联网公司和AI创业公司。他们更多是做大模型算法本身,以及围绕大模型的上层应用。
但顺着这条产业链向下看,却会发现在AI芯片与AI算法之间,还有非常关键的一层,这就是IT层。围绕AI大模型的爆发,产生了一系列存、算、网等IT设备升级,以及AI数据中心、私域大模型的市场需求。这些需求持续上涨,带来了IT行业的又一次爆发。
所以,当我们在讨论大模型产业链的时候,不能离开IT行业与IT企业。从2023年到现在,可以看到各个主要IT厂商纷纷出牌,抢滩大模型的新机会。这种趋势将在2024年持续上升,产生更加激烈的市场竞争。
IT大厂面对大模型,首先是做产品,找切口,继而开始形成连贯的智能化战略。
本文中我们希望和大家一起读懂,IT企业为何要抢滩大模型,又是如何实现这一战略目标的。
走向第三春,大模型带来的IT市场迭代
AI大模型的爆发,客观上给IT企业带来了巨大的机会。这是由于传统的IT设备,大多数都无法满足AI大模型的训练与部署需求。其中最知名的,就是AI需要专项算力。于是就产生了AI服务器这个全新的IT市场。再比如集群化AI训练,需要对数据中心的网络设备进行全面升级,以此来避免珍贵的AI算力在集群化过程中被浪费。
这些由大模型特殊性产生的IT设备迭代需求,伴随着AI技术的爆发给IT市场格局带来了显著影响。比如,根据TrendForce此前发布的数据,2023年全球AI服务器(包含搭载GPU、FPGA、ASIC等)出货量应该可以达到120万台,年增长率高达38.4%,并且市场规模上将占到整体服务器市场出货量的近9%。
如果这种情况持续下去,AI技术专项适配的IT设备,既是目前阶段的增长爆发点,也可能是未来市场的主流需求。因此没有IT厂商可以放弃大模型带来的战略契机。
回溯IT市场的发展历史,行业内经常将过去划分为早期IT市场的信息化时代,以及互联网兴起之后的数字化时代。那么伴随着AI大模型的全面渗透,市场很可能将迎来IT第三春,也就是智能化时代。
在智能化契机的序曲当中,还有一条不能忽视的主线,那就是IT技术的国产化。尤其在2023年,伴随着AI芯片禁令的反复炒作,AI算力国产化成为科技自主可控趋势中的重中之重。
国产化意味着新需求。这一需求与AI大模型带来的市场需求交融在一起,加重了这一轮IT市场迭代的分量。
面对走向IT第三春的可能,各个厂商纷纷开始寻找自己的AI市场切入口,同时注重提升自主可控AI产品的占比。
而分析IT厂商实现这一目标的战略,我们可以将其归纳为以下三种。
以高度,赢广度
IT厂商在切入大模型机遇时,首先要解决客户信任的问题。AI相关的IT基础设施选择很多,且差异化较小,用户试错成本巨大。所以如何能够与客户建立技术及解决方案信任是关键。
破解这个难题,有这样一种思路:厂商首先来把最核心、最难的事情完成,再通过核心市场来影响普及市场,形成以高打低,以高度赢广度的市场格局。
而AI领域的核心任务有两个。最复杂、庞大的基础设施是AI计算中心,而最复杂的AI任务是AI for Science。
而在这两个维度布局最深,并且已经赢得口碑的,应该是中科曙光。
AI for Science为代表的“重型AI”需求,具有算力规模大、多元算力融合、服务需求水平高的一系列特点。为了切入这个领域,早在2022年曙光就完成了算力一体化平台的开发及布局。依托各类算力中心,以原生的底层资源、市场化运营机制、开放生态体系,以及大量增值服务为支撑,为用户提供集“算力、数据、应用、运营、运维”的一体服务。
这一战略的代表性成果,就是曙光推出的5A级智算中心。在智算中心场景中,需要集中呈现厂商的技术、资源、生态、产学合作等AI行业要素。需要完成从技术投入到解决方案构建,再到运营支持、生态建设的一系列工作。因此在东数西算背景下,能够获得大量认可的智算中心,就会成为整个智能化IT生态中的战略高地,满足更多用户对厂商AI技术能力与生态能力的信任。
陆续建设并投入使用的5A智算中心,也就成为曙光在切入AI机遇时的高点。广泛带动了曙光在AI服务器、存储等领域的发展。同时,曙光在AI for Science的积极布局与成功经验,也成了其持续挺进AI机遇时的核心差异化要素。
目前来看,“以高带广”是IT厂商走进智能时代一个行之有效的策略。
以算法,带设备
相较于互联网企业与AI公司,更多有IT需求的企业其实并不了解AI,同时也很难探索满足自身业务需求的大模型落地方案。这也就导致更广泛的客户难以向AI方向转化。为了解决这个问题,在2023年我们看到了IT厂商开启了一种比较超越常规的探索:自己做AI大模型,并且开源。
去年11月,浪潮信息对外发布了完全开源且可免费商用的源2.0基础大模型。这个系列的AI大模型包含1026亿、518亿、21亿等不同的参数规模。对外称为是国内首个千亿参数、全面开源的大模型。在能力应用上,源2.0大模型可以执行多种任务,比如数理逻辑、代码生成、知识问答、中英文翻译、理解和生成等。
作为硬件供应商的IT企业,去做纯软件的开源大模型,似乎是一件打破常规的事。但在浪潮信息的动作中,我们却可以看到这个策略在“打开AI机遇切口”上的合理性。
首先,训练大模型的基础是硬件能力,尤其是算力能力。同时也会展现出厂商对软硬件适配能力的理解。比如说在算力层面,源2.0就采用了非均匀流水并行的训练方法,综合运用“流水线并行+优化器参数并行+数据并行”的策略,让模型在流水并行各阶段的显存占用量分布更均衡,避免出现显存瓶颈导致的训练效率降低的问题。这个方法为硬件差异较大的环境提供了新的训练方式。这样的经验展现、路径探索,可以帮助IT厂商更紧密了解客户的IT环境与AI训练需求,从而提供准确的产品及服务。而对于用户来说,先看懂厂商如何做算法,也可以有效指导自身的AI算法尝试,从而可以推动尝试与客户间的AI合作关系。
另一方面,IT厂商推出开源且可免费商用的大模型,等于将大量潜在客户的算法应用门槛降到最低,让他们可以开始尝试大模型。而在尝试成功之后,客户也自然会更倾向于开源模型背后,原厂提供的IT设备,从而实现了以软件带动硬件的市场策略。
这种策略能否收获积极的市场反馈,在2024年引起行业的效仿和跟随,让我们拭目以待。
以全栈,降门槛
在IT行业中,企业需要坚持产品和解决方案两条腿走路的策略。前者主攻出货量,而后者可以带来更为可观的利润空间。
而在AI大模型机遇到来时也是如此。相对来说,本身AI能力较强,应用相对成熟的企业会考虑购买AI相关的存、算、网IT产品。但更多的企业则没有强大的AI能力,但又对智能化能力有着需求和期待。这种情况下,就需要IT企业以解决方案的模式进行AI能力交付,从而降低企业的AI大模型门槛。
这也就引出了IT厂商入局大模型的第三种思路:发挥自身的全栈技术优势,提升解决方案交付能力。在降低企业AI应用门槛的前提下,获得更好的商业回馈。
这一点,可以说是IT厂商面对大模型机遇时的普遍选择。各家都是重兵投入,集结力量。一般来说,AI大模型相关的硬件设备有算力、存储、网络和商用终端,而在硬件基础上还有AI开发平台、管理平台、私域大模型等软件能力。在这各个领域有广泛布局的IT厂商,也就有了拥抱大模型机遇的更大底气。
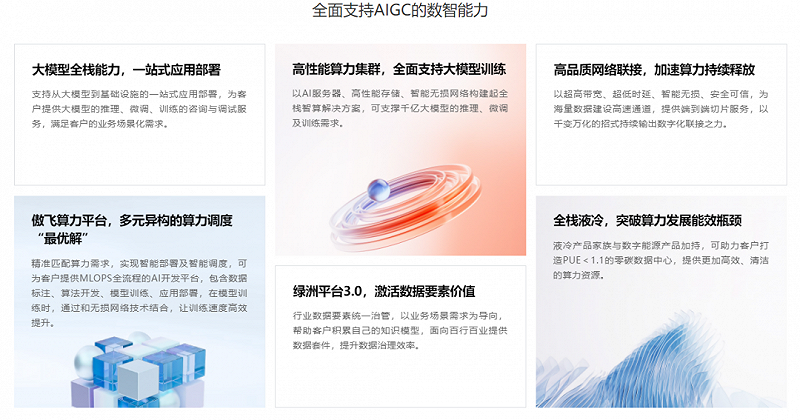
比如说,新华三面向AI大模型机遇,打造了百业灵犀LinSeer私域大模型,定位是为企业用户提供定制化服务的私域大模型。可以提供资料分析、代码编写等服务,覆盖了政府政务、工业制造等诸多领域。百业灵犀LinSeer私域大模型,可以与新华三此前的一系列AI布局进行结合,比如训练型智算服务器、推理型智算服务器、绿洲平台、傲飞算力平台、无损网络,高性能存储、液冷解决方案等,能够综合性帮助客户一站式部署智算底座,快速搭建AI场景化应用。
这种尽量发挥自身全栈技术优势,打通AI大模型所需软硬件底座的模式,在很多IT厂商的最新动作中都有展现。比如联想推出的大模型解决方案及服务,就包括智算中心、AI平台、AIforce的“三位一体”。面向私域大模型市场,联想也推出了帮助企业构建私有化大模型平台的服务,其依托于一站式端到端的解决方案与陪伴式服务,让客户不必考虑部署细节,就可以快速获得大模型能力。这一解决方案的建立,也融合了联想在IT基础设施、IT服务、AI force平台,以及智能终端领域的多种能力。
这种尽量将自身产业优势结合,形成整体性解决方案,从而提供低门槛AI获取方式的能力,是IT企业切入大模型机遇核心策略。比如我们可以看到新华三在切入大模型领域时,就将自身在网络、液冷等方面的优势融合进来。而联想则将自身在商用终端、AI能力平台上的积累纳入整体方案。
这种通过能力融合来构建差异化的策略,将在接下来IT厂商布局AI业务时展现得更加清晰。
整体来看,IT厂商抢滩大模型,是一种综合能力的考验,同时也需要厂商有调动、整合的能力,从而实现高举高打的系统性战略。
在这个过程中,有三个要素尤为关键。
一是厂商能否将多元化的布局协同起来,通过能力整合发挥出自身独特的AI优势。
二是能否实现软件侧对硬件侧的补充,甚至通过软件创新反哺IT基础设施市场。
三是技术自研以及全面国产化的能力,这点将在科技自主可控的浪潮中不断变得更加重要。
可以说,IT行业的AI迭代与智能化竞赛,才刚刚拉开序幕。