@科技新知 原创
作者丨余寐 编辑丨赛柯
六个月前,由OpenAI研发的文生视频大模型Sora横空出世,给了科技圈一点大大的震撼。
用AI生成视频并不是新鲜事,只不过此前一直无法突破合成10秒自然连贯视频的瓶颈。而Sora在发布时就已经能合成1分钟超长视频,视频质量画面也效果惊人。
尽管Sora一直没有开放公测供用户体验,但其底层架构还是被扒了个遍。被称之为“Sora路线”的DiT,全称为Diffusion Transformer,本质是把训练大模型方法机制融入到了扩散模型之中。
自此,相关平台不甘落后,纷纷摸着Sora过河,你方唱罢我登场,竞争不可谓不激烈。有媒体统计,国内有至少超20家公司推出了自研AI视频产品/模型。入局玩家纷杂。

在刚刚过去的7月,商汤推出最新AI视频模型 Vimi,阿里达摩院也发布AI视频创作平台“寻光”,爱诗科技则发布PixVerse V2,快手可灵宣布基础模型再次升级,并全面开放内测,智谱AI也宣布AI生成视频模型清影(Ying)正式上线智谱清言。互联网企业之间的赛场也有了新故事。字节跳动是第一批发布AI视频模型的选手,3月率先发布剪映Dreamina(即梦),三个月后,快手可灵AI正式开放内测。
AI视频大模型赛道如此之“卷”,究其原因,无疑是其背后蕴藏的商业空间与想象力。不过,用户更关心的是产品本身。这也是行业必须要直面的问题:AI视频大模型到了哪一步?Sora带来的“光环”,究竟值不值得期待?
目前深度学习的框架,“数据是燃料、模型是引擎、算力是加速器”。在掌握模型搭建方法后,不断投喂数据并提升算力和准确性是各平台采取的主要策略。而进展是有限的。普遍来看,大模型在生成具有连贯性和逻辑一致性的视频方面仍然存在困难。
本次我们选取几个国内头部视频生成模型进行实测,包括可灵、即梦、PixVerse、清影(智谱清言),具体直观地测试不同的模型表现。
为尽可能客观地比较测试结果,我们采用如下设定:
1.使用统一的中文提示词,包括简易提示词和复合提示词;
2.测试包含图生视频和文生视频两种方式;
3.测试场景包括大模型对人物、动物、城市建筑等的生成效果;
4.模拟新手用户使用场景,统一采用各模型平台电脑端默认设置;
5.展示呈现采用一次生成结果,不进行二次调整优化。
以下是各模型的实际生成效果:
场景1:二次创作场景
提示词:做出加油的动作后做出鬼脸,吐舌头并眨右眼。
场景说明:使用梗图《握拳宝宝》,模拟用户二次创作,测试模型对于图片的理解和生成能力。对于模型主要的难点在于需要理解“鬼脸”的含义,并能对“吐舌头”和“眨眼”两个动作做出反馈和生成。现阶段,模型一般只能识别一个动词。

网络上曾经爆火的“握拳宝宝”

↑即梦:主体的手部、嘴部产生了明显畸变,对于提示词动作的理解没有非常明显。

↑可灵:主体动作流畅自然,具有真实感,对于提示词动作理解不够到位。

↑PixVerse:主体动作流畅自然,能够做出提示词相关的动作,这是几个生成视频中唯一一个做出“眨眼”动作的模型。

↑清影:不敢说话了,我怕说错了一不小心被吃掉。
场景2:人物吃东西场景
提示词:一个亚洲年轻男性在家里用筷子津津有味地吃一碗面条,风格真实,类似于电影《天使爱美丽》,环境舒适温馨,镜头逐渐拉近对准人物。
场景说明:对于模型来说,需要围绕“亚洲年轻男性”“筷子”“面条”生成视频,同时要理解电影风格和环境,并按照指示进行运镜。更重要的是,通过吃饭这个场景可以更清晰地让模型展示手部细节,并通过吃面条这个动作来展示模型对于物理世界的理解。

↑即梦:第一帧很帅,光影也很自然。但依旧存在脸部和手部畸变的问题,以及模型明显不能够理解筷子的使用方式和面条的食用方式。

↑可灵:非常惊艳的视频!环境的光线、人物的坐姿和使用筷子的手部姿势都非常真实,甚至嘴部的油光反射都清晰可见,不愧是据说可灵最擅长的吃播领域。唯一是面条的运动轨迹有一些小暇疵。

↑PixVerse:惨不忍睹,甚至还被动卡出了一个不连贯的分镜,也没有理解运镜。

↑清影:如果不看主体人物动作,其实还算过得去。光线、环境和氛围都到位了。
场景3:动物拟人场景
提示词(简单版):一头大熊猫戴着金边眼镜在教室黑板前讲课。
提示词(复杂版):电影胶片感风格的场景中,一头大熊猫戴着金边眼镜,在教室黑板前讲课。它的动作自然流畅,周围是充满质感的教室环境,学生们认真听讲。整个场景如同电影画面,光影处理细腻,色彩饱满。电影胶片感风格,气氛温馨,8K电影级。
场景说明:该场景通过设置两版提示词,来测试大模型对于想象力的理解。简单版提示词仅有大熊猫、金边眼镜、黑板,模型可以通过这三个关键词生成具有可自主添加其他内容的视频,来展现模型的想象力和细节搭建;复杂版提示词按照清影内设的提示词调试小程序生成,涉及场景、风格、人物、环境、色彩、氛围和清晰度等,测试模型的细节刻画。
先看简单版提示词生成的效果:

↑即梦:很不错的视频生成,除了“金边眼镜”外,要素齐全,神态动作也非常自然,光影非常优秀。黑板上的字甚至有些以假乱真。

↑可灵:各种素材都齐了,但是没能特别理解讲课和吃竹子的区别。为了减少失误,画面整体相对单调,没有添加更多细节。

↑PixVerse:要素都齐全,风格也不错,就是眼镜稍微有点出戏(也比没有强)

↑清影:完全没有领悟提示词的意思表达
升级提示词后的效果:

↑即梦:效果依然不错,光影理解也在线,唯一小瑕疵还是眼镜部分,有畸变,以及好像不太能理解“讲课”这一场景的座位排列。

↑可灵:真·熊猫大师讲课图,没得说,优秀!

↑PixVerse:模型自己添加了运镜和细节成分,最后有一些扭曲,整体效果跟前一版差不多。

↑清影:有景深和运镜,画面质感还需要提升,相比前一版有了很大进步。
场景4:科技想象场景
提示词(简单版):充满科技感的未来城市一角,仰视视角。
提示词(复杂版):在充满科技感的科幻风格未来城市中,使用推近镜头,展现建筑和交通工具的细节,无人机在空中穿梭,天气晴朗,阳光洒在高楼大厦的玻璃幕墙上阳光透过高楼的缝隙洒下,周围环境充满未来感,科幻风格,气氛激昂明朗,HDR高动态。
场景说明:该场景同样设置两版关键词,简单版只给出科技感、城市和视角三个关键词,由模型填充生成剩下的内容;复杂版提示词同样使用清影的提示词调试程序生成,涉及风格、运镜、场景、环境、色彩、气氛和清晰度。一方面,该场景主要测试模型在不同颗粒度的提示词下所生成的视频内容丰富性;另一方面。“未来”是现实物理世界与想象世界的结合,可以测试模型对于建筑、光影和科幻的理解。
同样先看简单版:

↑即梦:运镜角度、色彩等方面做得都很好,突出了科技感,对于提示词的理解是到位的。

↑可灵:不出错的方案。建筑有畸变,对于“未来”的想象力有一些欠缺,仅仅是城市建筑的堆砌。不过能够在建筑外立面添加LED大屏,也算是一个亮点。

↑PixVerse:科幻感十足,交通工具、城市、环境都做得非常到位。不过好像没有特别理解仰视视角。

↑清影:倒是对仰视视角非常有心得体会,但是色彩和“未来城市”对理解依然还是差一些。
再看复杂提示词版生成效果:

↑即梦:很优秀的视频了,除去无人机的物理运动方式不能完全理解以外,对于提示词和风格的理解和把握非常到位。

↑可灵:依然是不会出错的方案,有一些畸变,就是看起来好像是北京动物园公交枢纽的实拍是怎么回事。

↑PixVerse:有点抽象的科幻,不太知道该怎么评价。畸变有些严重,但科幻感还是很足的。

↑清影:阳光很好,以至于只能看见玻璃幕墙。
除了场景应用,我们还从另外四个维度对所选取的四个大模型进行了测评:
视频生成质量和清晰度
内容生成准确性、一致性和丰富性
使用成本和价格
生成速度和交互界面
基于「科技新知」的测试情况,在视频质量和清晰度方面,可灵大模型在四个模型中更胜一筹,例如在生成大熊猫视频时,其能够较为清晰细腻地表现出大熊猫毛发的纹理、质感和色泽;对于物体的边框勾勒也区分明确,画面更真实,相对来说物体畸变也是最少的。清晰度方面,几个大模型生成效果都还不错,PixVerse效果相对落后。
从准确性和一致性比较,四个模型对于部分提示词的忽略是普遍情况。对于两个及以上动词,通常模型只会关注其中一个,侧重选择哪些关键词和关键信息也是考量模型理解能力的重要判断方式。
从生成视频的丰富性上,即梦和PixVerse表现较好。在一些除主体元素外的细节方面,二者都在尽量扩充内容,尤其是即梦对光线光影颇有理解。反观可灵,在这部分则相对保守,主要以保证主体元素和动作不出差错为主要聚焦。
从使用成本上,目前四个模型均可以免费或付费使用。具体来看,截至测评日,清影可以无限量使用,可灵、即梦和PicVerse则采用每日赠送积分点数的方式供用户体验。除此之外,每家的付费机制各有侧重。
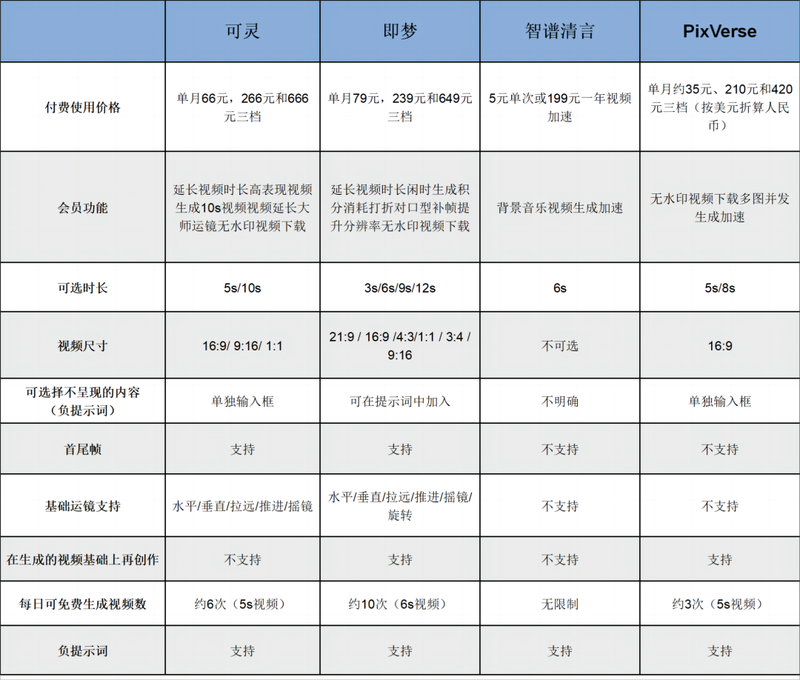
四个头部AI视频生成模型对比表
从生成速度上,我们同步实测了几个模型的生成速度,得到如下结果:
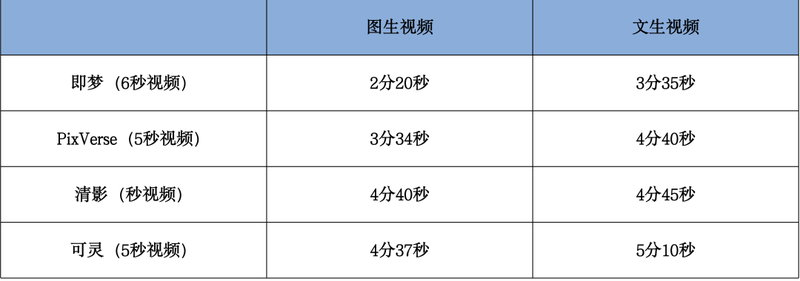
四个头部AI视频生成模型生成速度对比表(数据测试时间为8月3日上午11时)
从交互来看,在注册登录门槛上,清影仅采用手机验证码注册登录,相对简单;可灵支持手机验证码和快手账号两种登录方式,默认使用手机验证码;PixVerse则遵循海外主流产品的登录方式,提供谷歌、Discord绑定和邮箱三种登录方式;即梦带有一贯的字节系产品特色,比如在电脑端使用产品之前,需要先下载抖音才能扫码登录,当然也可以选择使用手机验证码登录,但又必须授权抖音验证。
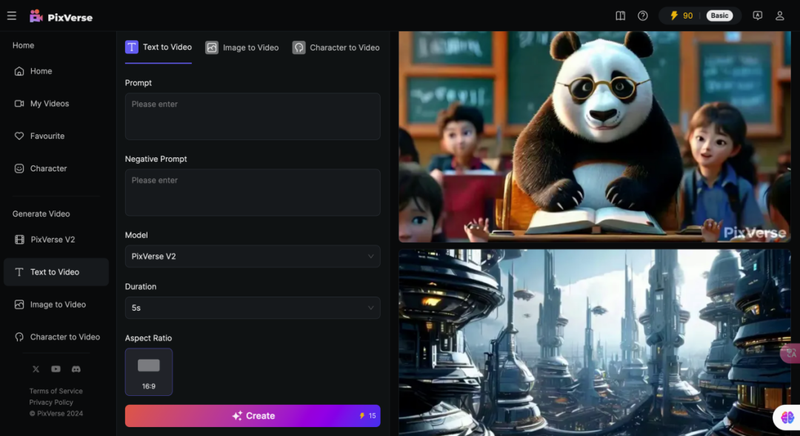
在页面布局上,PixVerse采用纯英文界面,右上角为账户等个人信息,左侧为功能性按钮,界面交互非常简单,可调节参数也并不多,主要是正向提示词、负提示词,模型选择,时长,画面比例等。
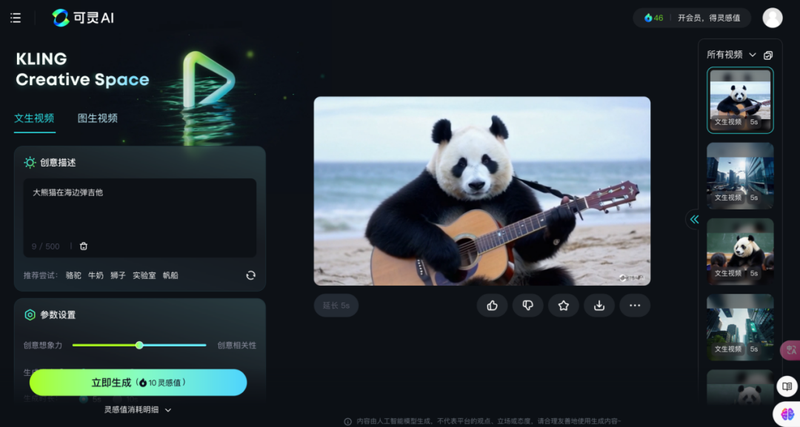
可灵的页面布局也类似,使用传统操作台界面,右上角为账户信息,左侧为调试台,中间为预览窗口,右侧为历史记录,动线流畅。可调节等参数包括正向提示词、创意想象力/创意相关性,生成模式、时长、视频比例、运镜、负提示词等。
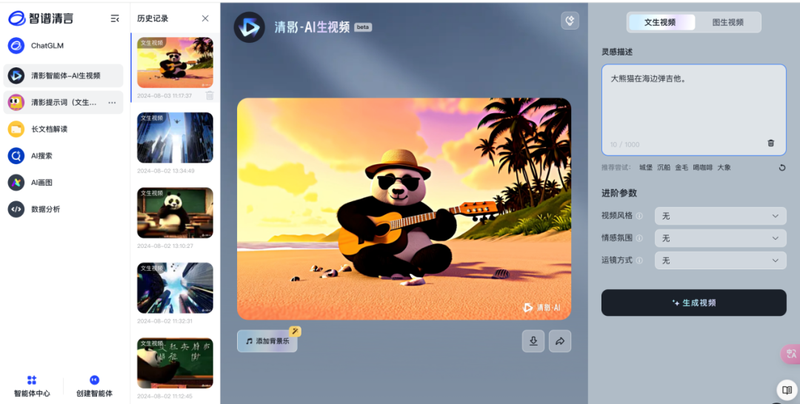
智谱清言将AI生成视频作为整个平台的一个子功能,嵌入到平台看板中,因此在界面布局上稍显杂乱。界面共分为四个部分,最左侧是平台的功能模块,再到历史记录、视频预览,对于生成视频可操作性不高。最右侧才是控制台,仅有提示词输入,视频风格、情感氛围和运镜方式可以选择,需要用户自行探索部分隐性功能,有一定学习门槛。
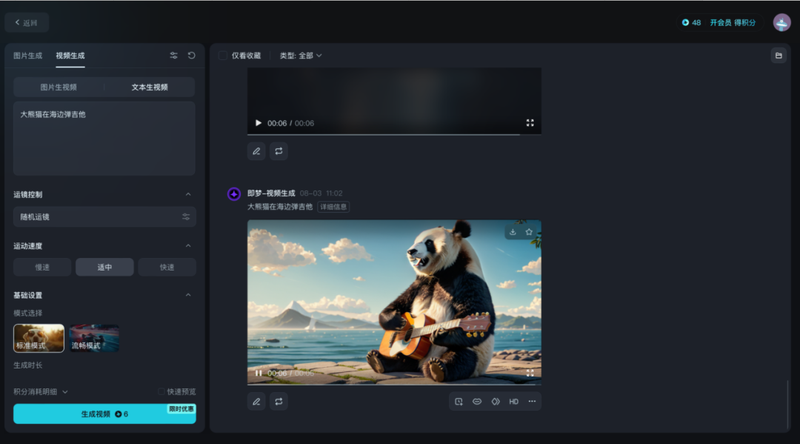
即梦模型主界面简洁,总体色调和布局承袭剪映的风格,分为左侧调试和右侧预览两部分,调试部分与其他模型大同小异。在右侧预览部分,对生成的视频可以实现延长时长、对口型、补帧、提升分辨率等会员功能,用于对生成视频的调整,也符合用户工作流习惯。
测评观察
总体使用下来,「科技新知」个人的感受是产品使用不及预期,颇有雷声大雨点小之意。就「科技新知」的测试体验而言,几款模型中体验最好的是可灵,不论是文生视频还是图生视频,相对来说都比较丝滑。对新手用户来说,不需要掌握非常复杂的提示词技巧,仅按照模型操作界面的提示,使用纯自然语言就能够达到相对满意的效果。另一方面,生成的视频在细节(比如手部)方面处理得较平滑,失误率较少。对于现阶段生成视频通常需要“抽卡”(碰运气)的赛道常态来说,减少失误率就意味着提升质量。
在本次测试场景的反馈中,即梦和PixVerse生成的视频质量相对不稳定,一定程度上表现出了模型稳定性还有待提升。而清影模型,不知是否因为训练素材的原因,生成的视频总是带有浓郁的色彩和卡通风格,让人不由想起B站“学了五年动画的朋友”系列。
技术的发展固然鼓舞人心。除了速度提升以外,不少AI视频生成模型已经初步具备了“理解”世界的能力。即在视频生成时可以理解物体运动过程中的物理世界,也能预测视频下一步可能发生什么。
但在实际应用层面,这类大模型的局限也很显然。5到10秒的可选视频长度对于用户来说稍显尴尬,很难进行任何故事性创作。目前最匹配的领域,或许只能是制作一些表情包或梗图二次创作。企业并非没有意识到问题,只是现实很骨感——长度限制是由开发成本导致的。现阶段在AI视频生成赛道上,玩家比的不只是技术,还有资金。为了“回血”,平台纷纷设计了会员机制,怎奈花的比挣的多得多。
据调查机构 Factorial Funds 的数据,以 Sora 为例,它 30 亿参数(主流猜测 )的训练成本,比 1.8 万亿参数的 GPT-4 还要多。这还只是训练,实际使用的推理成本要更多。国内有 AI 企业做过一个折算,生成一个差不多两分钟的视频,企业的成本是 180 元。收取的会员制费用相对于其研发成本来说简直是九牛一毛。
从这个层面看,像抖音、快手这类拥有短视频平台的玩家自带天然优势。一方面,其训练数据并不缺乏,另一方面,自身的海量用户也使企业更容易实现商业化路径的闭环。但变现门槛也无法忽视。设想一下,如果只是一名普通的C端用户,除了一开始的新鲜劲儿,如何保证其付费率和付费意愿?
因此,成为“中国版的Sora”远不是这场AI视频大模型竞赛的终点,而恰恰只是起点。产品问世之后,谁能找到可持续的商业化之路,落地产业化应用,才是国产AI赛道的终极玩家。