文|数据猿
2025年,注定是AI智能体爆发元年。
在这场流量和技术狂欢中,新技术动辄冠以“站起来”的光环,在这样的主旋律下,AI数据、案例乌龙往往被淹没在汹涌的正向洪流中,更有甚者提出问题会被怀疑居心。
但随着AI应用的深入,时下最火的DeepSeek也不可避免深陷“幻觉陷阱”泥潭。
一方面,从医疗诊断中的虚假处方,到法律文书中的虚构案例,再到新闻事件传播中的合成信息,AI的“谎言”正以流畅的逻辑、专业的表述渗透到现实。
今年2月,如果不是长期从事人口研究的中国人民大学教授李婷的公开辟谣,很多人都对“中国80后累计死亡率为5.20%”这组数据深信不疑,其背后原因很有可能是AI大模型出错。
另一方面,AI大模型也正成为谣言的放大器,从新闻消息到股市“黑嘴”,从网络平台虚假信息到被纳入信源范围、再到错误答案或谣言,已经形成完整闭环,从超一线明星到众多上市公司都被迫成为主角。
如最近疯传的“超一线明星在澳门输了10亿”的消息持续发酵,最后被证实是网民徐某强(男,36岁)为博取流量、谋取非法利益,使用软件“某书”中AI智慧生成功能,输入社会热点词制作了标题为“顶流明星被曝境外豪赌输光十亿身价引发舆论海啸”的谣言信息,最终被处以行政拘留8日的处罚。

再比如华胜天成、慈星股份因DeepSeek被推上风口浪尖等。

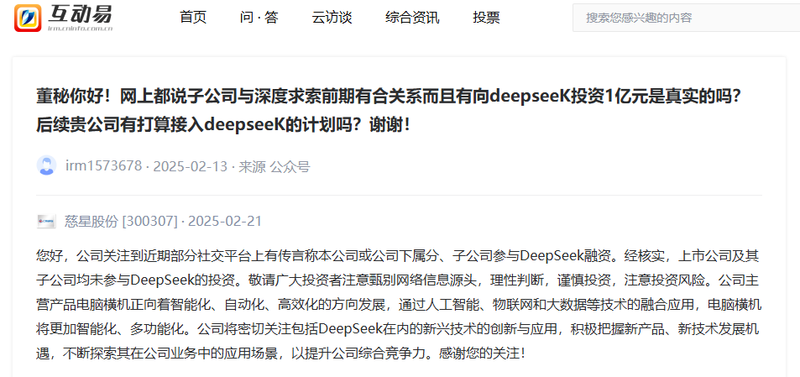
当AI幻觉从技术缺陷变为社会问题,人类该如何重建对AI的信任围墙。
AI幻觉的本质技术“想象力”的另一面
什么是AI幻觉?
简单来说,AI幻觉指的是AI也像人产生心理幻觉一样,在遇到自己不熟悉、不在知识范围的问题,编造难以明辨真假的细节,生成与事实相悖的答案,更笼统些,AI胡说八道的本领就是AI幻觉。
在现有技术水平下,AI幻觉比例其实非常高。来自Vectara机器学习团队的幻觉测试显示,截止到2025年2月28日,各主流AI大模型都或多或少存在AI幻觉问题。其中时下最火的
DeepSeek-R1,幻觉率高达14.3%,远超行业其他推理模型。数据显示,即使是DeepSeek-V3,幻觉率也高达3.9%,OpenAI-o1的测试结果是2.4%。
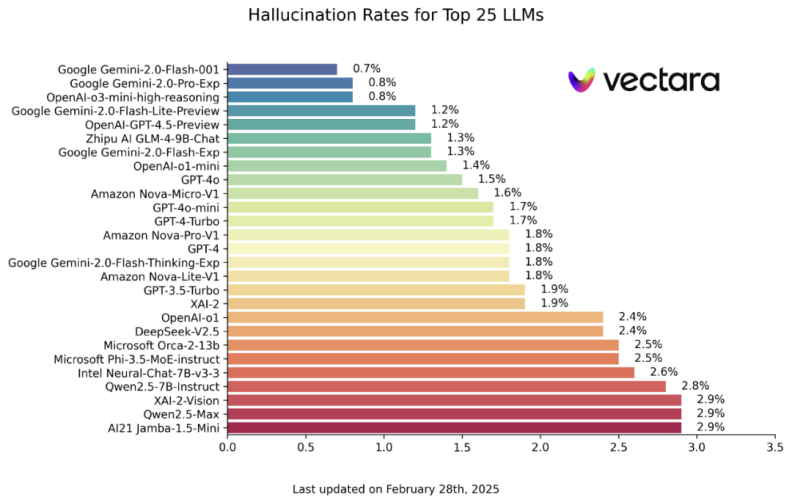
图片来源于Vectara
AI为什么会产生幻觉,要了解这个问题,首先要明白AI大模型的技术根源。
大模型的本质是一种对人类知识的数学化和统一化,背后是Transformer架构的出现、算力的提升、以及互联网海量文本及数据量的爆炸式增长。
其实AI大模型的工作流程比较清晰,输入文本 → 拆分为token → 神经网络数学变换 → 自注意力分析上下文 → 计算所有可能词的概率 → 选择输出词 → 循环生成结果。
整个过程本质是通过海量数据训练,让模型学习文本中的统计规律(如词与词的搭配概率、语义关联),而非真正“理解”内容。Transformer架构的生成逻辑,实则是场精心设计的赌博。每个token选择都是有概率分布的轮盘赌,当模型在“三马前两个是马云、马化腾”词条后以更高的概率选中“马明哲”时,马明哲就会成为问题的答案。
根据这个工作流程可以发现,AI幻觉的共性原因主要归结以下三点。
第一,基础训练数据的病根。
互联网发展几十年来,从来没有过信息精细化时代,无论是过去还是现在,互联网语料库的参差不齐和无法保障的准确度,都从根本上为AI幻觉埋下了病根。
无论是训练中可能包含的错误、偏见、虚构或者不完整的信息,模型自然会学习并复现这些错误。另外,如果问题超出训练数据的覆盖范围,模型可能依赖统计模式“编造”答案,而非基于真实知识。
第二,概率生成机制的设计矛盾。
通常来说,AI大模型被要求“流畅回答”而非“谨慎求证”,训练时更关注生成文本的流畅性(如语法正确、上下文连贯),而非事实准确性。因此在被提问到冷门问题时,AI宁可编造细节也不会回答“我不知道”。
与此同时,AI大模型生成过程中没有内置机制(如实时访问数据库)验证事实,导致错误无法被发现并及时修正。
第三,无法真正理解人类思维。
AI不具备人类的常识或物理世界的体验,无法验证生成内容是否符合现实逻辑,在某些任务上过度拟合训练数据或者泛化能力不足时,都有可能生成不合理内容。
此外,在通过人类反馈强化学习(RLHF)优化模型时,会出现过度迎合用户期望,比如提供看似详实的回答,而非严格追求真实。
因此,AI幻觉实则是从“数据缺陷”到“设计矛盾”的综合作用下的产物,是一种必然。
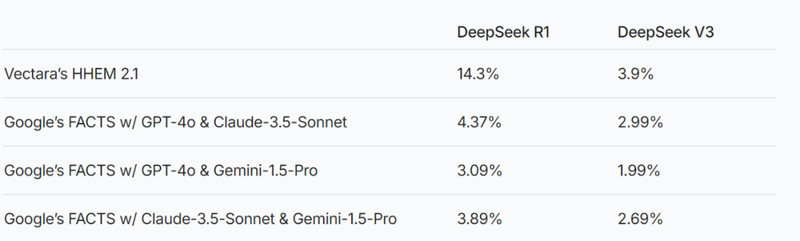
那么,为什么DeepSeek幻觉率要明显高很多?答案藏在其出色的推理能力里。
在Vectara机器学习团队的研究里,通过HHEM 2.1 来分析幻觉率,发现DeepSeek-R1 在幻觉率上比 DeepSeek-V3 高出了 大约 4 倍。
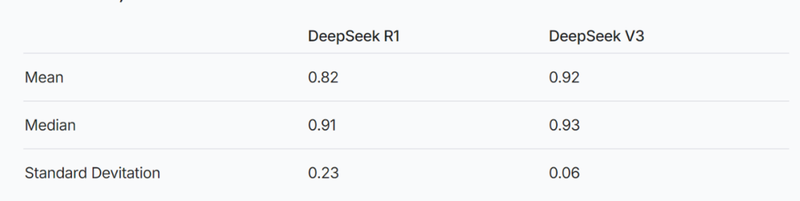
图片来源于Vectara
研究人员进一步提出,推理增强的模型可能会产生更多幻觉,而这一点在其他推理增强模型中也有所体现。例如,GPT 系列的 GPT-o1(推理增强)和 GPT-4o(普通版)之间的对比显示,推理增强模型的幻觉率通常也较高。
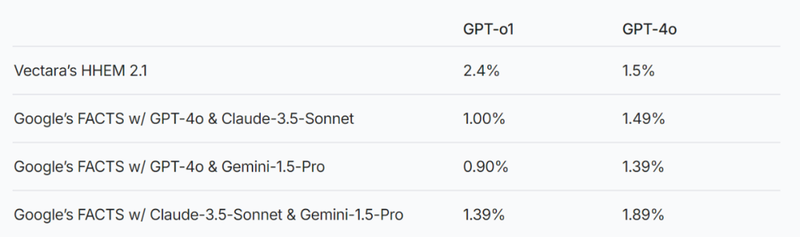
图片来源于Vectara
以此来看,推理增强模型可能会更容易产生幻觉,因为它们在推理过程中处理了更多复杂的推理逻辑,可能因此产生更多无法与数据源完全匹配的内容。
DeepSeek-R1 的推理能力虽然强大,但伴随其而来的幻觉问题也更为明显。但相较于DeepSeek, GPT-o1 的幻觉率较 GPT-4o 差距没有那么大,因此在实测阶段,GPT 系列在推理与幻觉之间的平衡显然做得比 DeepSeek好。
较高的幻觉率,更容易生成与真实数据不符或者偏离用户指令的现场,而在医疗、法律、金融等对准确性要求高的领域,AI会带来严重的后果。
DeepSeek-R1在这方面尤其明显,在撰写专业内容时,尽管已经前置化要求信源准确,但DeepSeek给出的答案依然差强人意。在讨论AI医疗方面的问题,DeepSeek给出了详细的数据及信源,但图中所有数据及信源,绝大部分为虚构。例如DeepSeek回答中的Google的Vision Transformer ViT-22B,2023年报告达90.45%,实际上是Transformer进阶版ViT-G/14在2021年的数据,
在比如“AI系统(如Google Health 2023年研究)在乳腺钼靶影像中达到92%准确率,略低于人类放射科医生的96.3%(NHS临床试验数据)”中,实际上是Google Health在2020年《自然》上发表的论文,其中结论是研究人员让人工智能系统与6名放射科医生进行对比,结果发现人工智能系统在准确检测乳腺癌方面优于放射科医生,DeepSeek显然张冠李戴的同时,又以极专业的表述让人信服。


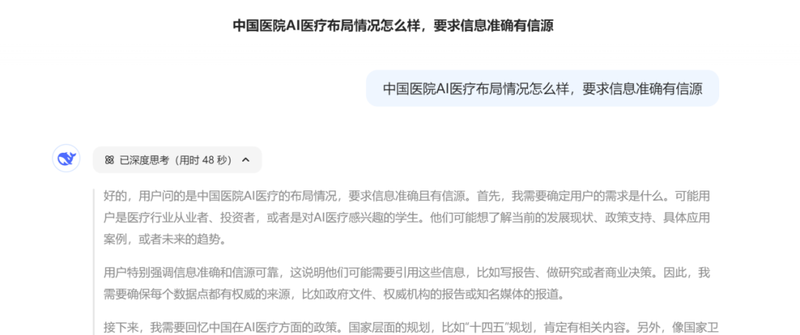
再比如,当询问DeepSeek中国医院AI医疗布局情况,DeepSeek给出的回答同样漏洞百出,经核查大部分为虚构信息。


早在去年,互联网大佬周鸿祎和李彦宏就曾因为AI幻觉问题进行过观点交锋。
在去年全球互联网大会上,周鸿祎明确指出,大模型幻觉不可消除,幻觉是大模型与生俱来的特点,没有幻觉就没有智能,人与很多动物的区别就是人能描绘不存在的事情,这就叫杜撰的能力。
而在那之前,李彦宏表示“要想基于大模型开发应用,消除幻觉是必须的,如果这个模型总是一本正经地胡说八道,就不会有人信你,就不会有应用。”并强调经历了2年左右的发展,大模型基本消除了幻觉,它回答问题的准确性大幅提升了,这让AI变得可用、可被信赖。
事实上,周鸿祎和李彦宏的观点基本上是行业中对于AI幻觉的两个看法,怕AI没有创造力,又怕AI乱幻想。但就现阶段而言,AI幻觉的危害已经显现出来。
当AI开始说谎,人类后真相时代可能提前到来
毫无疑问,AI幻觉,正在侵蚀人类真实世界,我们正面临一场前所未有的信息真实性“战争”。
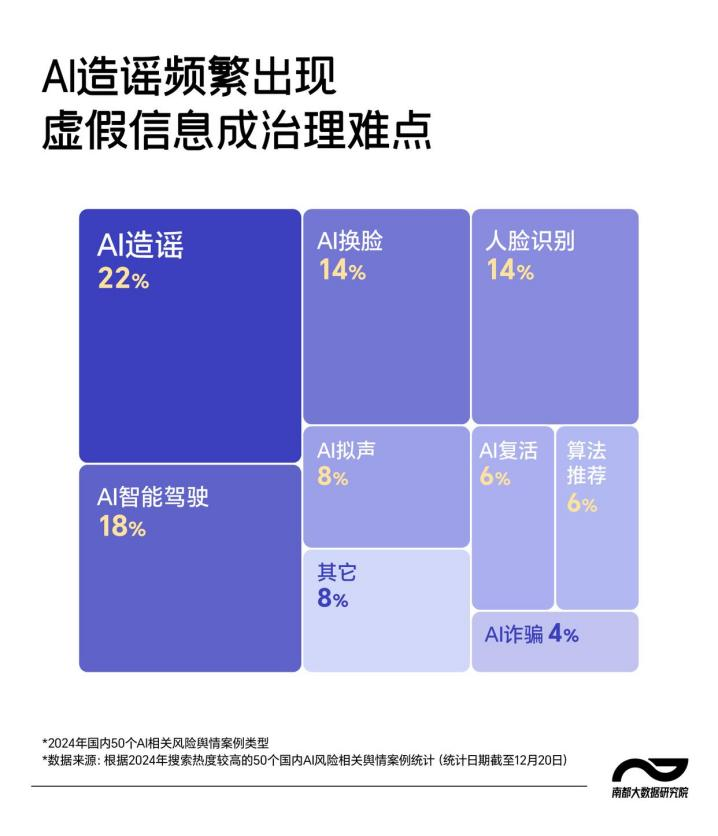
据南都大数据研究院发布的“AI新治向”专题报道,2024年搜索热度较高的50个国内AI风险相关舆情案例中,超1/5与AI造谣有关,AI谣言,已经成为社会公害。
另外,68%的网民曾因AI生成的“专家解读”“权威数据”而误信谣言。作为新技术,很多人对AI给出的答案深信不疑,但AI数据的真实性却无人担保。
中国信通院相关负责人透露,中国信通院曾做过试验,当在特定论坛连续发布百余条虚假信息后,主流大模型对对标问题的回答置信度就会从百分之十几快速飙升。这就像在纯净水中滴入墨水,当污染源足够密集,整个知识体系都会被扭曲。
今年年初,纽约大学研究团队在《自然医学》杂志上发表的论文中指出,如果训练数据中被注入了虚假信息,LLM模型依然可能在一些开放源代码的评估基准上表现得与未受影响的模型一样好。这意味着,我们可能无法察觉到这些模型潜在的风险。
为了验证这一点,研究团队对一个名为 “The Pile” 的训练数据集进行了实验,他们在其中故意加入了150,000篇 AI 生成的医疗虚假文章。仅用24小时,他们就生成了这些内容,研究表明,给数据集替换0.001% 的内容,即使是一个小小的1百万个训练标记,也能导致有害内容增加4.8%。这个过程的成本极其低廉,仅花费了5美元。
如今这些漏洞,正在被大肆利用,通过自动化脚本在多个论坛同步投放虚假信息,接着利用爬虫技术加速搜索引擎收录,最后用污染后的AI回答进行社交媒体裂变传播,已经形成一个完整黑色产业链。
美国麻省理工学院传媒实验室曾在一个报告中表示,假新闻在社交媒体的传播速度是真实新闻的6倍。而如今,AI加持下,谣言生产成本会大幅降低。
在公共安全事故中,AI谣言不仅会扰乱视听、干扰救援节奏,还容易引发民众恐慌。当造谣者通过收割流量,社会付出的代价其实是信任的崩塌与秩序的混乱。
不夸张的说,AI所制造的虚假信息已经影响了美国政治,如特朗普在竞选中所引用的非法移民食用宠物的图片,就是AI合成;而马斯克所引用的USAID付给克林顿女儿切尔西·克林顿8400万美元的信息,也是AI所编造。
世界经济论坛发布的《2025年全球风险报告》显示,“错误和虚假信息”是2025年全球面临的五大风险之一,从新闻到股市到谣言,AI正成为没有情感的帮凶。
与之对应的医疗风险、法律陷阱和学术造假,也会短时间成为社会公害。
更严重的是,我们可能会提前进入后真相时代。
牛津字典把“后真相”定义为“诉诸情感及个人信念,较客观事实更能影响民意”。
和“网络谣言”、“虚假信息”和“宣传操控”等话题的关注点有所不同,“后真相”并不强调信息准确与否的重要性,而是强调舆论分裂和极化的根本原因,是人们倾向于选择那些他们更愿意接受的信息,并将其当做“真相”。
在娱乐至上的现在,人们往往在还没弄清楚真相的同时,就已经在情绪的驱动下莫名其妙站了队。而真相从来不是单一维度的,它是由多层次、多角度的复杂信息交织而成的。从利用AI幻觉,到利用AI制造幻觉,AI正以人类未曾想过的方式影响着这个世界。
错的或许不是AI,是利用AI缺陷的人,但在流量时代,人类信息甄别能力在丧失,这不是一个好现象。因此,是时候行动起来了。
如何应对AI幻觉泛滥,技术修补和社会联防外更需自身谨慎
AI幻觉问题本身是AI技术问题,在短时间内也很难通过技术手段完全规避。
但借助网络和社交媒体,前沿技术潮流到普通民众的速度太快了,很多人都还没做好接受新技术的准备,就被涌来的浪潮裹挟前行,更有甚者成为了镰刀或韭菜。
AI幻觉治理,已经箭在弦上,具体方案无外乎技术修补和社会联防。
技术修补主要依赖技术平台和内容平台双向努力。
在技术修补层面,各AI大模型平台都需要慎重处理互联网海量文本筛选,加强数据监管,确保AI训练数据的真实性和合法性,防止数据污染。
同时要通过AI技术比如自然语言处理(NLP)技术,分析数据的语义、逻辑结构,识别文本中的矛盾、不合理表述,尽量避免数据投喂中涌入虚假信息。
此外,要合理处理推理能力和准确性的平衡。前文说到,DeepSeek-R1有较高的幻觉率,但其在推理能力方面确实较为出色,创造力和准确度,是AI大模型天平的两端,任何一端失衡,都会出现致命问题。
目前已经有很多团队在开发AI生成内容检测技术,让AI生成内容自带“水印”等隐藏符号,也能够有效甄别AI幻觉生成内容。如腾讯混元安全团队朱雀实验室研发了一款AI生成图片检测系统,通过AI模型来捕捉真实图片与AI生图之间的各类差异,最终测试检出率达95%以上,以后此类工具和技术会越来越多。
对于内容平台来说,互联网上海量数据,绝大部分以内容平台为信息传播渠道。无论是百度、抖音、今日头条、微博、快手还是小红书,都应该守好内容底线,及时发现,及时治理,及时辟谣,同时要组建专业审核团队,不让AI幻觉产出的内容及利用AI产出的虚假内容在互联网扩散。
与此同时,相关法律法规和政策也需要尽快落实。更重要的是,用户自己要学会辨别虚假信息,加强防范意识。对AI坚持“保持警惕,交叉验证,引导模型,联网搜索和享受创意”的原则,谨慎且拥抱。
就目前而言,无论是今日头条、还是百家号亦或是微信公众号,AI生成内容已经泛滥,如何治理,是各平台亟需思考的问题。
但有一点是可以肯定的,对于DeepSeek等AI大模型来说,AI技术的科技之光,不能让深信它们的普通民众为漏洞买单。