文 | 智能相对论
作者 | 陈泊丞
日前,英伟达CEO黄仁勋和Meta创始人马克・扎克伯格开展了一场“炉边谈话”。
两人作为当今人工智能领域的领袖人物,一边凭借AI芯片的绝对优势占据着算力领域的至高地位,另一边借助开源大模型Llama 3.1强势崛起成为开源领域的标杆。这样的对话为未来AI的发展趋势呈现了不同的视角。

黄仁勋对话扎克伯格
两位大咖的对话为我们描绘了AI技术未来的发展蓝图:从开源的AI算法,到先进的人形机器人,到未来即将普及的智能眼镜,AI技术发展充满了机遇与挑战。未来AI手机、AIPC、AI汽车、智能眼镜、服务器等等各类产品都会实现智能化升级,复杂的模型、海量的数据和计算,都极大地依赖于AI算力支持。
AI算力也正在从专用计算扩展到所有的计算场景,逐步形成“一切计算皆AI”的格局。
事实上,算力厂商们的动作也见证了市场对算力发展的要求。一方面,CPU、GPU、NPU等各种PU,也都被用于了AI计算。
另一方面,在适配不同场景应用的通用服务器上,浪潮信息也在致力于提供兼具高性能与低成本的选择。前不久,基于2U4路旗舰通用服务器NF8260G7,浪潮信息创新采用领先的张量并行、NF4模型量化等技术,实现了服务器仅依靠4颗CPU即可运行千亿参数“源2.0”大模型,再度成为通用AI算力的新标杆。
在今天的市场上,算力的产业地位正在迅速崛起。对应人工智能发展的三驾马车,算力、算法、数据三者终于到达了一个地位相当的状态,走向“并驾齐驱”。
要知道,在AI技术发展的前期,中国庞大的互联网用户群体和丰富的在线数据资源,侧重于数据的发展。而美国在计算机科学、数学和统计学等基础学科方面有着悠久的研究传统,则更聚焦算法的研发。对比两者,算力在前期的关注度就显得弱了许多。
时至今日,三驾马车并驾齐驱。大众对人工智能的发展思路也愈发清晰——AI产业的爆发是算法、算力与数据三者协同发展的结果。而这样的状态也就代表着AI产业正在进入一个全新的阶段。
人工智能产业来到了“过弯点”
现阶段,大模型技术的加速迭代,带来了千亿级大模型的持续涌现与精进。相关的AI应用也在以前所未有的速度和规模渗透到各行各业,并融入日常的生活和工作中。
人工智能产业正在从初步探索进入到了广泛应用的“过弯点”。在这个过程中,AI的三驾马车也到了全面协同发展的关键时刻,才能为场景应用的跨越式升级提供必要的技术支持。
以银行的防欺诈系统为例,早期的系统是基于大数据构建的,通过经验预设规则和统计模型来判断、检测可疑交易。如今,基于更高性能的通用算力整合大数据系统和金融防诈的AI模型,银行防欺诈系统实现了功能升级,不仅具备更高的准确性和更低的误报率,而且还能够根据新的数据自我学习和调整,快速适应新的欺诈模式。
算法、算力和数据三者协同,构成当前AI应用的基本范式。一个成功的AI项目往往需要在这三个方面都做出适当的投入和优化。
算法相当于AI的大脑,负责处理信息、学习知识、做出决策。而数据是算法的基础,如果没有足够的数据,即使是再先进的算法也无法发挥出应有的效果。
而在此基础上,不管是算法的运行还是数据的处理,都离不开算力的支持。特别是在涉及到大量的数据处理、复杂的模型训练以及实时的推理需求等场景中,AI对算力的要求,同时随着场景的规模化普及,还得进一步兼顾经济性。
现如今,针对AI产业的三驾马车,算法、算力和数据层面的升级依旧在同步进行,三者之间的协同在AI行业发展的驱动下达到了新高度。AI产业的加速发展,需要三驾马车的步伐更加一致。
是时候全面调整三驾马车的状态了
人工智能的广泛应用必然要建立在三驾马车协同发展的基础上。在接下来的时间内,针对人工智能产业的升级就需要解决一个关键问题,即如何保持三驾马车并驾齐驱的稳定状态。
一、技术“并驾”:一马当先并非最佳,三马同行最为稳定。
算力、算法、数据三者相辅相成,单一的技术领先无法带来AI产业的全面爆发,必须要另外两项迅速补齐,才能对应解决相关的技术问题。
例如,在当前,千亿级参数、甚至万亿级参数的大模型加速发展,带来了更强大的信息处理和决策能力,为智能涌现提供了基础。但是,算法层面的突破,必然要有算力、数据层面的升级,才能发挥出应用的效果。简单来说,如果没有足够的算力带动千亿级大模型的训练、推理等需求,那么再强大的模型也没有“用武之地”。
要加速人工智能的发展,支撑千行百业最广泛的通用场景,千亿级大模型必须要和大数据、数据库、云等场景相融合,实现高效运行。
但这一目标对计算、内存、通信等硬件资源需求量非常大。为了满足更多用户的AI算力需求,算力厂商不得不考虑如何有针对性地去克服现有的算力瓶颈。以承载千亿参数大模型推理的NF8260G7 AI通用服务器来看,浪潮信息在这方面就做出了专业的设计。
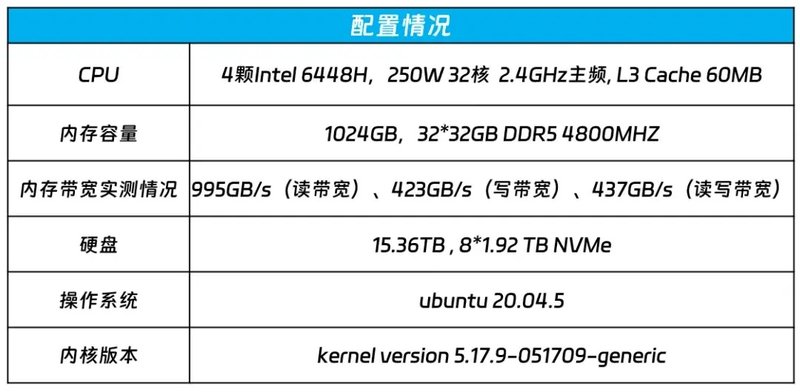
针对千亿级大模型推理过程中的低时延以及所需的巨大内存需求,NF8260G7服务器配置了4颗具有AMX的AI加速功能的英特尔至强处理器,内存方面,NF8260G7配置32根32G DDR5 4800MHZ的内存,内存带宽实测值分别为995GB/s(读带宽)、423GB/s(写带宽)、437GB/s(读写带宽),为满足千亿大模型低延时和多处理器的并发推理计算打下基础。同时,浪潮信息还对CPU之间、CPU与内存之间的高速互联信号走线路径和阻抗连续性做了优化,从而更好地支撑大规模并发计算。
这样的设计与升级,旨在面向算法,进行算力的优化,为接下来千亿级大模型的规模化应用提供了一个非常关键的支撑。
二、系统“齐驱”:三马拉车,重在系统性优化。
随着AI技术的发展,算力、算法、数据三者的系统性越来越强。很多科技巨头都在竞相发力寻找「模型水平高、算力门槛低」的人工智能方案。AI相关的解决方案不再是单一技术的应用,而是综合多个领域的突破实现整体系统性的升级。
举个例子,谷歌的EfficientNet模型通过优化网络架构,在ImageNet数据集上的精度相比传统模型提升了约6%,而所需计算量减少了70%。可见,当前大模型厂商在推动算力升级的过程中,也会考虑到软件层面的创新,提高算力和算法之间的适配运行能力。
为了能让通用服务器更好的运行千亿级大模型,浪潮信息除了对服务器本身进行创新升级外,也对千亿级大模型的参数规模做了优化。基于源2.0的算法研发积累,浪潮信息将1026亿参数的源2.0大模型卷积算子进行张量切分,为通用服务器进行高效的张量并行计算提供了可能,最终提高了推理计算效率。

基于CPU服务器的并行计算
同时,在这个过程中,浪潮信息还采用了NF4量化技术,对模型进行“瘦身”,提高了推理的解码效率等等。

NF4量化技术
当算力、算法走向协同,系统性优化的结果,是建立在两者协同的基础之上,最终目的在于为AI产业的落地提供一个稳定、强大的技术底座。未来,AI产业的全面爆发就需要以更系统的理念去驱动三驾马车的发展。
三、应用“加速”:产业落地需要“三驾马车”的综合最优解。
AI不再是实验室的产物,而是市场竞争的商品。不管是千亿级大模型的涌现,或是算力解决方案的升级,其根本的目标都是推动AI应用的加速落地,走向大众,带来实际性的经济效益。因此,在技术层面之外,行业还需要考虑经济层面的问题。
对比来看,尽管以英伟达GPU芯片为核心的AI服务器在处理机器学习、深度学习等高性能计算任务方面表现卓越,但是浪潮信息等算力厂商依旧致力于研发和升级以CPU为核心的通用服务器,这是为什么?
根本原因就在于CPU在通用计算、能效比以及成本效益方面仍然不可替代。特别是关系成本效益的经济性问题,本来就是当前限制诸多场景应用规模化落地发展的关键因素。因为AI专用基础设施的成本居高不下,普通的企业很难承受。而浪潮信息则是提供了一个更低成本、同时兼顾高性能的经济性选择,恰恰正是市场需要的。
基于通用服务器NF8260G7的软硬件协同创新,浪潮信息成功实现了千亿级大模型在通用服务器的推理部署,同时还提供了性能更强,成本更经济的选择,让AI大模型应用可以与云、大数据、数据库等应用能够实现更紧密的融合,助力产业高质量发展。这样的综合最优解,才是产业实现规模化爆发最需要的条件。
结语
AI三驾马车的系统性已经成型,更强大的算力可以支持更复杂的算法模型,从而更好地处理大规模数据。同时,高质量的数据集有助于提升算法的效果,反过来又需要更强大的算力来处理。而算法的进步也可以减少对算力的需求,通过更高效的模型设计降低计算成本。
这种系统性的形成,将极大推动人工智能产业的发展,也为现阶段AI厂商们的产品升级、技术迭代、服务进阶提供了一个关键的大方向。但同时,也意味着新的挑战,即如何去整合算力、算法和数据三者之间的技术与资源,成就新的突破。
*本文图片均来源于网络