
图片来自视觉中国
蓝鲸新闻12月20日讯(记者 武静静)要衡量一个大模型能力是否够强,评测是最直接的维度。大模型评测就是为大模型的一场“考试”,从不同大模型的表现中,不仅可以衡量现有技术水平,还能帮助识别大模型存在的问题,促进模型开发。
一个理想的假设是,如果一套大模型评测体系足够科学,就可以一目了然看到国内外大模型能力彼此的差距。但现实要比理想复杂的多,如果把大模型测评看作一场考试,它要面对的大模型考生掌握了多种语言,跨领域知识丰富,且一旦让他习得这次考试的考题,它可以依靠刷分获得高成绩。
几十种大模型评测榜单眼花缭乱
据蓝鲸新闻根据公开资料统计,全球针对大模型的评测榜单不下于50个,不同机构打造的大模型评测体系也不一样。
经常有人看到戏剧性的一幕,某模型在某个榜单上排名前三,但在一些榜单上却排在后面。这也引发了很多人的质疑,有人称,如果做不到公平可信,评测的价值就不大。
在这种复杂环境下,如何把大模型评测体系做的更科学?更有公信力?为此,蓝鲸新闻与国内最早探索大模型评测体系的机构,即智源研究院相关人士做了深入交流。
2023年,智源研究院推出了FlagEval(天秤)大语言模型评测体系,该评测体系覆盖语言模型、多模态模型、语音语言模型等多种模态,并针对不同模态设计相应的评测指标和方法。12月19日,智源再次发布了迭代后新版本的FlagEval,目前FlagEval已覆盖全球800多个开闭源模型,有超200万条评测题目。
为了设置统一的起跑线,开源模型采用模型发布方推荐的推理代码和运行环境。智源研究院智能评测组负责人杨熙告诉蓝鲸新闻,评测中,所有闭源大模型题目都是智源通过调用公开的API,以普通用户的角度来使用大模型,针对每个模型出的题目和访问方式都是一样的。“它可能不知道在评测,也不知道是测试数据。”
我们经常能看到大模型公司都在通过“晒自己在评测榜单中名列前茅”来显示自己的能力地位。而业内,也不乏有些公司一味“刷分”来证明自己的模型能力。
针对一些大模型榜单的刷分动作花样百出,有公司反复提交不同版本的模型直到得到满意的成绩为止,也有公司提前获取评测数据集并在训练过程中使用这些数据,从而让模型对测试内容有所准备,导致评测结果不能真实反映模型的能力。更有甚者会针对特定评测数据集进行过度拟合,使得模型在这个特定的数据集上表现得非常好,但在实际应用中却无法达到同样的性能。
此外,由于提示词等各种客观因素,大模型评测确实面临很多现实的挑战,为了确保评测结果的公正性和可靠性,智源也采取了一系列措施来避免大模型在评测中刷分。
杨熙向蓝鲸新闻举了一个例子,在多模态和语言模型的评测中,智源通过引入更难的考题来拉开模型之间能力的差距。更新后的考题使得模型得分中位数从之前的51分降至47分,有效避免了因题目过于简单而导致的分数虚高现象。
杨熙介绍,智源研究院使用的评测数据集不仅包括来自开源社区的公开数据集,也涵盖了其自身构建的自建数据集,确保模型不会仅仅针对特定数据集进行优化。
让大模型互相打辩论来一较高下
一个更新颖的方式让大模型互相打辩论,一争高下,来让人直观的感受到模型能力的差距。
和传统的评测方法相比,辩论赛要求模型理解辩题、构建论点、反驳对方观点,可以更全面地考察模型的思辨能力、逻辑推理能力、语言表达能力等综合素质,这有助于促进模型在复杂任务上的能力提升,例如批判性思维、策略制定、说服力等。此前在2018年,OpenAI就提出了一种人工智能安全技术,训练智能体对话题进行辩论,然后由人判断输赢。
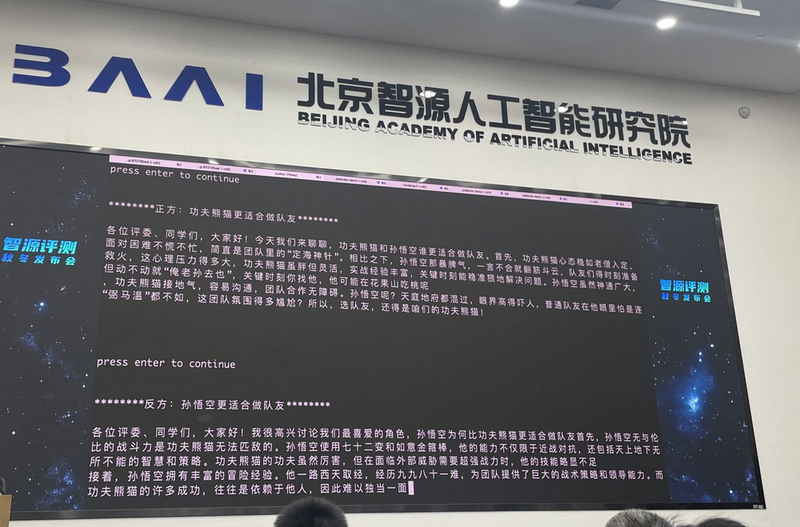
智源在现场演示了一场大模型之前的实时辩论赛。其中一场辩题是:“功夫熊猫和孙悟空谁更适合做队友?”
两个大模型展开了三轮对话,不仅能反驳对方观点,还能引经据典,谈话张力十足。也是在这些互动中,普通人更直观的感受到了不同模型的能力差异。
更多创新的大模型评测体系正在随着技术而不断演进。“榜单排名不应作为评价模型的唯一标准。”智源研究院副院长兼总工程师林咏华告诉蓝鲸新闻。
林咏华认为,用户在选择模型时,应根据自身需求和应用场景,综合考虑模型的各项指标,而非仅仅关注排名。此外,她也提到,评测需要更加关注模型的实际应用能力。单纯的理论指标并不能完全反映模型在实际应用中的表现,评测应更加贴近实际使用场景,例如响应速度、用户体验等。
“大模型评测是一个复杂的系统工程,需要行业共同努力,不断探索新的评测方法,构建更加高质量的评测数据集,并加强合作,推动统一评测标准的建立,才能更好地促进大模型技术的健康发展。”林咏华总结道。