文|数智前线 赵艳秋
在打造十万卡集群上,几家国内头部企业已有动作。
在11月12日举办的百度世界2024大会上,百度集团执行副总裁、百度智能云事业群总裁沈抖透露,为了支撑大模型进一步的高速发展,百度在打磨十万卡集群能力方面,已在两大问题上取得关键突破。与此同时,字节和阿里在智算上投入巨大,今年以来,华为也联合厂商在攻克更大规模集群。
是否有必要打造十万卡集群?过去24个月,由于大模型超级应用还未出现,中国业界出现了反思——大模型全球性的狂热,究竟是一场新的技术革命,还是新一轮泡沫?
在这次大会上,百度创始人李彦宏披露了一个数字,文心大模型日均调用量达到15亿,而6个月前是2亿。“‘应用来了’,代表了我们对大模型和生成式AI当下的认知和判断。” 李彦宏称。这个在下半年突然变得陡峭的曲线,在一定程度上给出了佐证。
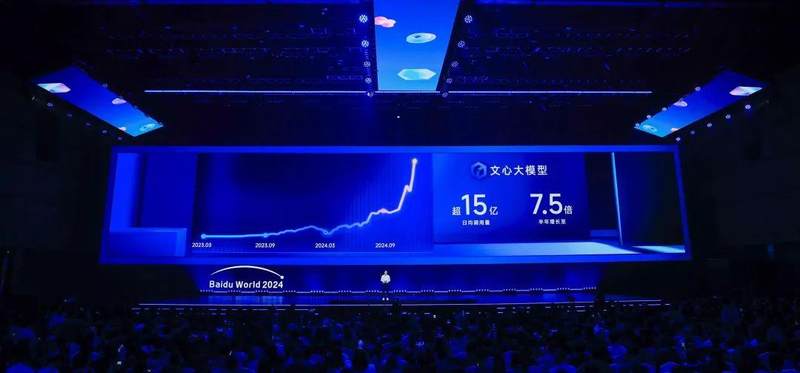
这也是当下中国云厂商开展技术准备的现实考量。由于投入和芯片上的限制,中国云厂商的表现并不激进。但他们在客户快速增长的需求下,也在分步走向十万卡集群。
企业智算投资的热情高了
百度杰出系统架构师王雁鹏,最近几个月频繁接触到高校客户,“他们对算力的需求在增多”。
今年诺贝尔物理学奖、化学奖都颁给了人工智能相关专家,引发了广泛关注。“大家最兴奋的是,原来AI for Science要由各种不同的模型去做,但现在搞蛋白质的、搞数学的......都可以‘揉’到大模型的方式中来,核心架构甚至全都是transformer。”王雁鹏告诉数智前线。高校的热情普遍提高了,最近预算变多,都拿到资金建设智算基础设施。
像上海交通大学,已转变传统科研模式,期望科学与AI更紧密的结合。他们与百度智能云合作建成了自己的AI for Science科学数据开源开放平台,支撑白玉兰科学大模型的训练。依托AI for Science平台,上海交大已在Nature Computational Science封面,发表了AI+城市的科学成果。在公开招投标平台上,近期更多高校发布智算相关招标公告。
车企是当下智算的采购大户。“我们调研,用户已愿意为好用的智驾买单。”一位大型车企人士说。而且,端到端智驾技术,比原来由很多小模型串联起来的智驾“更拟人化”,成为行业的主流方案。明确的方向,让车企投入意愿更强烈。该人士判断,未来1~2年内,车企智算算力会再翻两番左右。

“在教育行业,最大的梦想就是实现大规模因材施教。”好未来集团CTO田密说,“AI老师让我们看到了一丝曙光。有了大模型,所有的AI教育科技都值得重做一遍。” 大模型可以解题、讲题、口语练习、批改作业,为学生做个性化学习推荐。
“大厂可以从零开始做,小厂通过API调用或微调、RAG就可以。作为中厂或垂直领域的龙头企业,我们还是要基于最优秀的开源模型,做好后训练。”田密说。去年,好未来推出九章大模型MathGPT。为此,好未来在百度智能云上,自有和租赁数千卡,这在教育行业中是最好最高的。大模型在以各种形式落地,如学习机、App,也通过API向社会开放,手机、平板、PC和新能源车都开始了调用。

在餐饮行业,消费者已不知不觉用上了大模型技术。“百胜中国是最早开始使用生成式AI的餐饮企业。”百胜中国CTO张雷说。它是国内规模最大的餐饮公司。在人们经常使用的App小程序、外卖平台各渠道中,百胜采用了百度智能云的客悦AI智能客服系统,解决肯德基、必胜客在线点餐中非常多样化的服务需求,每天已协助处理超15万次消费者沟通。
张雷称,未来将以AI原生方式,在管理、运营、生产和交易的各个方面进行技术重构。
从去年开始,国家电网基于文心大模型和千帆平台,结合电力行业高质量数据,在共创电力行业大模型基础底座,在调度、设备、营销等六大专业领域探索AI原生应用。近期国网就会正式对外发布相关成果。

“我理解,所有行业都已被transformer给重构了。”好未来田密说。越来越多的大中型互联网企业、车企、头部央企等,都在训练自己的行业或企业大模型。
他们的共同特点是,有大量私域数据和独有业务,有研发力量,但不会从头去训练通用大模型,而是在开源或商用模型上做深入的后训练,适配各类场景,搭建自己的数据飞轮,并有商业预期。这些企业的需求,也进一步拉动了智算市场。
值得关注的是,在大模型范式下,算力与算法的重要性开始对等了,这让企业的投入占比发生了变化。
“我们算了一笔账。四五年前开始研发智驾时,要投入相当多的算法和规则开发工程师,人力、数据和算力的投入比是6:2:2。”一位车企人士说,“但现在端到端智驾研发,需要更大的算力。我们初步预测,上述比例将变为2:3:5,50%甚至更高的投入是算力。”
有趣的是,这些龙头企业无论采用公有云,还是自建数据中心,都不约而同找到了云厂商。“我们主动找到了百度智能云。”好未来田密说,“你会发现,在Infra(基础设施)的投入上,只有大厂才能做得这么细致。”

而IDC中国研究总监刘丽辉介绍,到2026年,半数以上的企业,都会与云厂商达成生成式AI基础设施、相关平台工具等方面的合作。
压力给到了云厂商
百度王雁鹏观察,在投入踊跃的企业中,行业龙头典型的算力需求在1000卡~5000卡规模,而大模型创企的需求则在万卡水平。
这些企业在训练和推理过程中,遇到了各种问题,他们对智算基础设施提出了四个主要的诉求——高速网络互联、集群稳定性、资源利用率、大模型训练和推理工具等。而这些需求与CPU云时代截然不同。
比如有人把GPU比作赛车,要让赛车性能发挥到极致,就要给它建立专业赛道。在搭建GPU集群时,企业要求云厂商提供一个更好的网络硬件互联架构。
稳定性是一件要命的事。CPU的功耗只有两三百瓦,GPU已经1500瓦了。黄仁勋因此被戏称为“核弹狂魔”。功耗高代表着集成度高,这就容易出故障。“我们算过,一个千卡集群,按照现有市场价格,一天的租金是二三十万元。平台稳定性不好了,我们的损失就很大。”一家车企人士说。而视频大模型企业生数科技人士告诉数智前线,他们核心的诉求是“稳定性”。平台稳定,确保他们在视频生成的核心技术“高一致性”上实现突破。
资源利用率也是企业最关注的问题,因为GPU太贵了,利用率左右着ROI。
而这些诉求,把压力给到了云厂商。“过去一年多,大模型正在重构AI计算模式。”一位云厂商的资深人士说,“我从来没有看到过任何一个技术浪潮,能够像这一轮大模型,从上到下对我们的技术有如此大的颠覆。”
此前,基础设施是以CPU为核心的体系。它的核心点是极致弹性、极致性价比,大家最大的驱动力是提效降本。

到了大模型时代,基础设施转向了极致高密、极致互联与极致规模。国外今年已从十万卡向百万卡集群迈进。用不了太长时间,可能一个数据中心,就会“缩到”一个机柜里或一个节点上。
基础设施从过去的提效降本,转变成一个全面追求技术创新,来驱动整个业务大发展的阶段。每一个从业者也都在朝着如何能够去追赶上scaling law的发展去奔跑。在一次会议中,百度集团副总裁侯震宇介绍,最近几年,在百度内部提及最多的是800G/T级互联、高密存储、异地异网异构调度、训推一体.....
由于过去十多年在整体AI上的投入,百度从2009年开始,在中国互联网企业中第一家开始使用GPU做集群加速,2021年已建成三四千卡单一任务的GPU集群,并逐步形成了有丰富技术栈的百度百舸异构计算平台。
“CPU的IaaS是一个通用平台,但GPU的IaaS不一样,更追求GPU算力端到端的性能最优,要给它提供更厚的技术栈,算力才容易发挥出来。”百度王雁鹏对数智前线解释。

基于百度百舸的技术栈,解决了龙头企业在算力上的问题。在长安汽车,最初GPU综合利用率不太高。长安汽车和百度智能云,应用百舸平台,做好训练任务的编排和调度,GPU利用率提升了40%以上。
视频大模型创企生数科技称,基于百度百舸稳定的超大算力集群,在OpenAI推出Sora仅40天后,推出了自研视频大模型Vidu。在训练中,他们应用了百舸平台的算力集群的任务分发、队列调度和训练加速,“缩短了 Vidu的研发周期”。
“我们迭代的速度是非常快的,无论是新功能,还是模型基础能力上。”在Vidu上线逾百日之际,生数科技在11月13日推出Vidu 1.5新版本,率先攻克“多主体一致性”难题。
由于最早在市场上推出模型,生数科技已在影视、动画、文旅有落地。比如,近期漫威电影《毒液3》的中国水墨风格AI宣传片,就是Vidu生成的。
奔向十万卡
国内云计算厂商还在更进一步,但他们的做法和考量也更理性和现实。
在海外,美国市场在经历了一个充分有效的竞争后,之前很热闹的大模型公司都在卖身,今年做基础大模型的企业已迅速收缩到五家——OpenAI、Anthropic、Meta、谷歌,以及马斯克旗下的xAI。
而这些巨头的算力竞争门槛已达到十万卡规模。微软计划到明年底,向 OpenAI 提供约30万个英伟达最新GB200图形处理器。但OpenAI似乎并不满意,也与甲骨文达成了协议,甲骨文正在设计一个超级数据中心,将达到一千兆瓦电力,转换过来就是50多万卡英伟达GPU;
Meta的小扎也不甘落后,称Llama 4模型正在一个10万片H100 GPU集群上训练;马斯克的xAI今年7月已建成十万卡集群,并将在未来几个月内再增加10万卡,其中5万卡将是英伟达H200。
在百度世界2024大会上,沈抖披露,百度已解决了10万卡集群两个难题。一个是在一云多芯情况下,两种芯片混合训练效能折损,控制在5%以内,这是业界领先水平。这一技术是针对芯片供应紧张,以及部分企业对国产算力有强需求而研发。
另一个难题是跨地域机房部署,百舸将单一训练任务集群的性能折损控制在4%以内,这也是业界领先水平。它解决的是电力问题和机房空间问题。10万卡集群一天要吃掉300万千瓦时电力,相当于北京东城区一天的居民用电量;所需的占地,相当于14 个标准足球场。它通过高效拓扑结构、跨地域无拥塞高性能网络和高效模型并行训练等方案,在横跨几十公里的多机房上实现。
不过,业界如今有一个疑问,OpenAI在2020年提出的Scaling Law是否还成立?是否有必要追赶十万卡集群?王雁鹏坦言,他们看到Scaling Law确实在放缓。这也是OpenAI o1比较火的一个原因,它采用强化学习(Self-play)模式,开创了模型scaling的新维度。
一些国内龙头企业,其实在半年多前已将更多精力转向强化学习。通过算力创造更多数据,由人们给每一步打分、做数据标注,通过奖励模型去强化它,让模型更智能。

强化学习让模型训练对算力的需求也降低了不少。但这并不意味着国内就原地踏步在数千卡到万卡集群。大模型正进入更多产业,王雁鹏预估,明年算力需求还会以训练为主,算力需求在高速增长,企业对算力在性能和成本上,也提出进一步的诉求。
“比如大模型创企,他们有很强的融资压力,所以对成本的诉求非常强。”王雁鹏说。
当下,公有云是企业进行大模型训练的主流方式。云厂商常常采用“服务一个企业,搭建一个集群的方式”。但这种方式存在明显劣势,即在企业训练任务不处于高峰期时,集群中的计算资源处于闲置状态,造成资源浪费。而当10万卡集群出现后,云厂商就可以依靠这个大型集群,为众多企业提供服务,根据不同企业的需求,动态分配计算资源,不仅提高了资源利用率,也降低了企业的成本。
“当我们能解决了十万卡集群技术,比如上述的跨地域RDMA技术、多芯混训技术、容错技术,就可以不需要建一个大的单一机房,而是把几个机房融合在一起,提供一个更好的云平台,也给大家一个更好的成本。多芯技术也是一样的逻辑。”他进一步说。
在与国内企业的相互合作和推动下,中国云厂商正在加速平台建设,推动大模型技术浪潮,在市场的快速演进。