作者|蓝媒汇 陶然
国内最顶尖的这些大模型初创公司,现在站到了该做取舍的十字路口。
十月初,市场中传出消息,称智谱AI、零一万物、MiniMax、百川智能、月之暗面、阶跃星辰这六家被称为“AI六小虎”的中国大模型独角兽中,有两家公司已经决定逐步放弃预训练模型,缩减了预训练算法团队人数,业务重心转向AI应用。
所谓预训练,一般指的是利用大规模数据对模型进行无特定任务的初步训练,让模型学习到通用的语言模式、知识和特征等。
好比是给一个还不太懂事的孩子(模型)看大量资料(大规模数据),让他在这个过程中不断学习各种知识、认识各种事物的样子和规律(通用的语言模式、知识和特征)。
虽然这个孩子一开始并不知道具体要做什么任务,但通过广泛学习,会形成相对全面的知识储备。
之后,如果要让这个孩子去完成特定的任务,比如写作文、做数学题等,就可以针对这些具体任务专门优化适配。

但问题是,这种笼统的大规模训练往往价格不菲,且过程多有不确定性,每次基础模型迭代的训练成本动辄就会达到百万、千万甚至数亿美金这个量级。
在讨论AI行业现状的播客中,Anthropic创始人 Dario Amodei 与挪威银行首席执行Nicolai Tangen曾谈到,虽然目前许多模型的训练成本为 1 亿美元,但“当今正在训练的”一些模型的成本接近 10 亿美元,且这个数字未来还会上涨。
Amodei 表示,人工智能训练成本将在“2025 年、2026 年,也许还有 2027 年”达到 100 亿美元至 1000 亿美元大关,他再次预测,100 亿美元的模型可能会在明年的某个时候开始出现。
一向激进的马斯克为了让自家 xAI的Grok系列模型后来居上, 更是大手笔屯集了10万张昂贵的GPU卡。

对于这些不缺资源的头部玩家来说,预训练是一个必选项。
但对“AI六小虎”而言,中间过程的黑箱特质,叠加投入产出比的压力,让预训练的“做与不做”,成了摆在眼前一个现实问题。
预训练,是模型地基,更是大模型公司技术试金石
预训练的好处显而易见——模型可以获得更广泛的语言理解能力和基础的智能表现,为后续针对特定任务的微调提供良好的基础。它可以是后续产品研发和应用设计的强大起点,缩短开发周期,适应不同需求。
当年GPT-3横空出世,预训练过程为其后续在各种自然语言处理任务中的出色表现奠定了坚实基础。在预训练阶段,GPT-3 使用了海量的互联网文本数据,通过无监督学习的方式让模型学习语言的统计规律和语义知识。例如,在问答任务中,经过预训练的 GPT-3 能够理解问题的含义,并根据其在预训练中学习到的知识生成准确的答案。
但相对应的,预训练也需要用到大量的算力资源和高质量数据,以及复杂的算法和技术。
简言之,预训练的效果取决于两方面:能力和资源。前者对应算法的先进性、数据的质量和规模以及工程师的技术水平等因素,决定了模型能够学习到多少知识和技能;后者对应计算资源的投入、数据采集和处理的成本、人才等,决定了预训练能够进行到何种程度和规模。
OpenAI团队在预训练GPT-3和GPT-4过程中消耗了大量的算力资源和高质量数据。为了训练GPT-3,OpenAI使用了微软提供的超级计算机系统,该系统拥有超285,000个CPU核心和10,000个GPU,训练一次的费用高达460万美元,总成本约1200万美元。
GPT-3的训练消耗了约3640 PF-days的算力,使用了45TB的预训练数据,包括CommonCrawl、网络文本、维基百科等。
而在训练GPT-4时,OpenAI使用了混合专家模型(MoE),包含1.8万亿参数,通过16个专家模型来控制成本。每次前向传播使用约2800亿参数和560 TFLOPs。
据斯坦福HAI研究所发布的AI Index报告显示,OpenAI的GPT-4训练成本约为7800万美元。
模型架构和算力需求使得其训练和部署需要大量的高性能计算资源,也就是来自英伟达的A100或H100 GPU。

o1发布之后,很多人开始大谈后训练的重要性。后训练可以显著提升模型在特定任务上的性能,但是它无法改变模型在预训练阶段学到的基础特征表示。换句话说,预训练很大程度上影响着模型性能的基准线和潜在的上限。
LlaMa 67B 与LlaMa 3.1 70B 的模型后训练上限是不同的。同理,如果一个公司能够在预训练阶段训练出优于LlaMa的自有模型,那么与在LlaMa基础上后训练的公司相比,前者就具备了技术上的天然优势。
这种优势的建立,需要技术能力,也需要算力资源——能力和资源,成为了大模型预训练的两个门槛。
谁放弃?谁掉队?
这里的能力,并非跟自家的上一代模型相比,而是跟行业现有公开成果相比,也就是那些头部的开源大模型。
像是由Meta推出、被广泛调用的LlaMa系列、马斯克旗下xAI公司的Grok-1,以及国内阿里云开源的部分Qwen系列模型,都已经具备相当优秀且全面的基础能力。
而资源,自然指向的是训练结果的投入产出比:如果一家公司花费大量资源去做预训练,得来的成果却比不上那些开源的模型,那继续坚持做预训练就没什么必要了。那么这种训练就纯粹的浪费资源,毫无价值可言。这里的资源既包含算力、资金,也包含技术人才。
众所周知,国内大模型“小虎”有六七家公司,智谱AI、MiniMax、零一万物、月之暗面、百川智能、阶跃星辰、DeepSeek。在大模型预训练上,各家面临的难题各不相同,现状不一。或许我们可以从基座模型成绩上“窥一斑而知全豹”。
由LMSYS组织的全球大模型竞技场(ChatBot Arena)是全球头部大模型企业同台竞技的权威盲测平台。在最新一期的榜单上,依次出现了零一万物的Yi-Lightning、智谱 AI 的GLM-4-Plus以及DeepSeek V2.5,这些模型都在榜单上取得了出色的成绩。
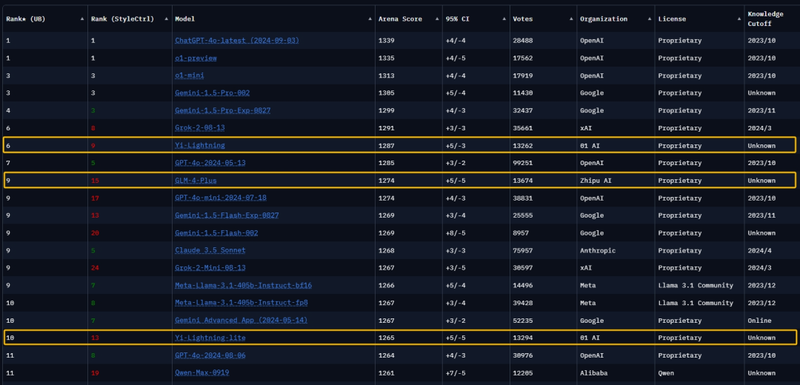
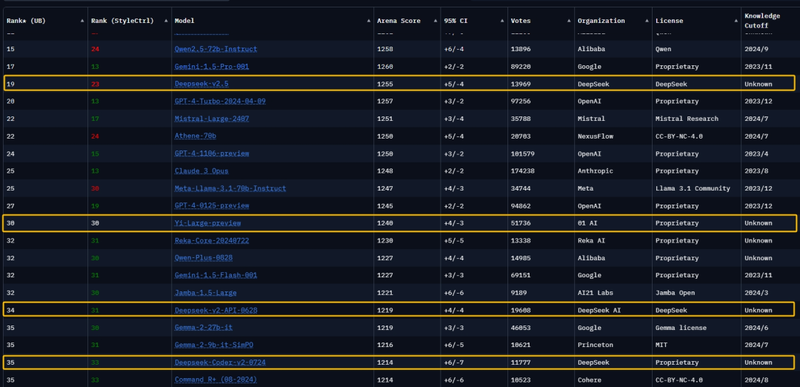
智谱 AI 一向有着“清华系国家队”的称号,背后的主导人物唐杰也是中国在人工智能和大模型领域颇具话语权和声量的学术领军人物,找融资找算力不在话下;零一万物创始人李开复同样在AI领域深耕多年,公司早早布局AI Infra,近期也宣布了新融资,资金算力都不成问题;DeepSeek背靠幻方量化,坐拥上万张GPU,也没有道理在算力充盈的情况下,放弃预训练。
相比之下,另外几位玩家的现状就显得有些“模糊”:
月之暗面从成立第一天起便亮明了ToC的决心,也由此成为多家巨头青睐的对象,目前也是大模型初创中估值最高的企业。但除首次发布会上发布Moonshot大模型(后改名为Kimi大模型)、并宣布聚焦长文本能力之外,月之暗面再未对外透露更多基座模型的消息。业内更有声音传出,月之暗面的基座模型是在已有模型基础上微调得来的,缝合了多种工程模块后才达到了目前的效果。
而实际上,大模型预训练除长文本之外,还有诸多技术点同样值得攻坚:MoE(Mixture of Experts,混合专家模型)模型架构、多模态、RAG(Retrieval-augmented Generation,检索增强生成)、SSM(Structured State Space Models,结构化状态空间序列模型)、o1的COT(Chain of Thought,思维链) tokens、RL(Reinforcement Learning,强化学习)。这些都需要真金白银与技术人才的投入,对于发力ToC应用、选择在营销获客方面大量投入的月之暗面而言,继续去做大模型预训练,投入产出比似乎并不高。
背靠上海国投的阶跃星辰、MiniMax同样不缺资源。据上观新闻报道,上海国投已经与阶跃星辰、MiniMax签署了战略合作协议。
但单就预训练阶段来说,MiniMax似乎面临着与月之暗面同样的尴尬局面。MiniMax的海外应用矩阵中,Talkie已成为头部出海产品,海螺引起全球瞩目,但ABAB大模型很久未有新进展,也没有在LMSYS等平台上出现。
在诸位“小虎”中最晚亮相的阶跃星辰则急于证明自己的技术实力,年中密集地发布了千亿参数Step-1和万亿参数Step-2。在阶跃星辰的宣发中,Step-2 万亿参数语言大模型的模型性能逼近 GPT-4,但在LiveBench、Arena-Hard、MT-Bench等国际权威Benchmark上成绩仍弱于GPT-4-1107。
越发活跃的阶跃星辰的另一面,则是技术低调的百川智能。从2023年8个月发布8款模型,到2024年仅发布3款模型,百川智能在基座模型上的脚步在不断降速。最新一代基座大模型Baichuan 4选择打榜国内商业化榜单SuperCLUE,如LMSYS ChatBot Arena、AlpacaEval 等有学术背景、相对公正的国际权威榜单上,Baichuan大模型却未上榜或未获好成绩。

其实,对于预训练“知难而退”,并非一种难以启齿的消极行为。甚至,在当前的大环境下,对于某些公司来说,是一个极为理智的选择。
当前行业基础模型过剩却少有破圈应用产品涌现。锤子多而钉子少。利用行业中头部资源、开源大模型去做调优,出应用产品,务实的选择才更能在大模型的红海中找到适合自己身份,节省资源同时创造价值。
只是在选择放弃预训练的同时,也意味着走下了AGI的牌桌,将自家模型和应用的上限拱手让于开源模型。
至此,什么样的玩家,可以留在AI预训练这场豪赌的牌桌,答案日渐清晰。
预训练成大模型公司灵魂考验,人才流动频繁
从尖端芯片到美元投资,中美之间在科技领域的竞争会愈演愈烈。LlaMa、Mixtral等开源模型系列未来前景如何仍未可知。根据美国政府最新发布的信息,美国即将出台限制某些针对中国人工智能投资的新规,相关规则目前正在最终审核阶段,预计会在一周内发布。
掌握预训练能力,才能保证自己不下全球大模型竞争的牌桌。随着中美科技角力的加剧,顶尖人才资源的争夺战已然成为焦点,一场围绕人才的战略较量早已爆发。
有多位长期关注AI领域的猎头反馈称,自ChatGPT爆火之后,国内对于AI领域的顶级研发人才的需求持续走高。
国内的人才争夺同样激烈。如阿里通义千问大模型技术负责人周畅近期被曝出离职消息;曾任职于旷视研究院的周昕宇选择加盟月之暗面;秦禹嘉被曝从面壁智能离职后,2024年初创立序智科技,数月后加入字节跳动大模型研究院。
原滴滴出行AI Labs首席算法工程师李先刚更是被曝在一年多时间内从贝壳跳槽到零一万物、百川智能两家“AI小虎”公司,前阵子被曝又回到贝壳。“猎头圈爆料,他先从贝壳到零一万物,再到百川智能,又回贝壳,每家公司都只待了几个月。”
2023年初时曾传出“字节跳动以140万美元年薪从OpenAI挖人”的传闻。2024年6月,李开复也曾在接受媒体采访时表示,自己已经化身世界上最大的AI猎头招揽世界上最优秀的人才。随后零一万物便公开表态,已有多位负责模型训练、AI Infra、多模态和产品的国际大咖于数月前加盟。
人才资源的投入在模型预训练方面立竿见影。字节跳动自研豆包大模型一经发布便在业内以高性价比闻名。零一万物也被传团队调整,但并未影响到模型进展——仅用了2000张GPU、1个半月时间就训练出了超越GPT-4o(5月份版本)的Yi-Lightning,这也是目前中国大模型公司在LMSYS榜单上的历史最佳成绩。
一位资深大模型从业者告诉笔者,预训练人才在顶尖公司之间互相流动是非常正常的现象,OpenAI、Google、微软、Meta、xAI之间也是如此。
“一个模型性能要做到世界第一梯队,而且又快又便宜,让用户都用得好用得起,需要这个大模型公司的模型训练团队、AI Infra团队都具备世界顶尖水准,而且要深度共建共创,才能‘多快好省’地做出顶尖模型。”上述从业者说,“随着竞争壁垒越来越高,‘单靠挖一位算法负责人就能搞定一切’,这是非常不切实际的想法。”
在这方面,国内头部大模型公司也是“八仙过海、各显神通”。阿里巴巴、字节跳动本身具备丰富的算力资源, DeepSeek背后的幻方量化也曾豪掷千金购置了上万张GPU。零一万物则选择从Day 1起“模基共建”,邀请来自阿里、华为等大厂的高管、骨干加盟组建AI Infra核心团队。

英国《金融时报》近期报道给出了一份“第一阵营名单”,初创“小虎”零一万物、DeepSeek通过MoE模型架构和推理优化,大厂阿里巴巴、字节跳动等凭借着技术、资源训练出了具备国际竞争力的模型,阿里的Qwen、字节的Doubao、零一的Yi、DeepSeek系列模型即便在海外同样享有极高知名度。
从模型性能的角度来说,坚持预训练不仅将模型上限掌握在了自己手中,同时也牢牢把握住了推理成本的优化空间。只有从头到尾走过预训练的路,才能够深入了解模型架构,与AI Infra团队深度共建,以软硬件协同逼近理论上的最低推理成本。
从应用落地的角度来讲,一个关键点除了成本,还有安全性——模型是否自主可控。与接入开源模型相比,走过从0到1整个过程的自研预训练模型无疑是更加安全可控的。对于企业级和政府级客户而言,这一点尤为关键,因为这直接关系到他们的核心利益和关切。
换言之,无论是从基座模型的角度,还是从应用落地的角度,预训练能力都是大模型企业的“压舱石”。而对于预训练本身,经过能力和资源两道门槛的区隔之后,注定会是一场玩家不多的游戏。因为高手,本就应该不多。
阿里巴巴、字节跳动等大厂入局之后,大模型初创公司在资源方面的劣势一览无遗。也正因如此,能力方面的重要性得以凸显,如何以各家技术实力追平资源差距是每家大模型初创公司都需要思考的问题。
LlaMa 3.1 405B、Qwen-Max等顶尖开源模型的发布像是一次次的警钟,催促着大模型初创公司尽早做出选择。
算法、AI Infra能力强,能够以各种方式降低训模成本和推理成本;资源整合能力强,能够支撑公司不断在模型预训练上作出新尝试。
能力与资源并举,才是大模型时代能全局掌控的“硬指标”。中国大模型“小虎”们道路已经出现分野,从预训练开始,技术领先者已经脱颖而出。有人下牌桌、有人走新路。
只是,掉队后再赶上的难度,会越来越高。