文|无相商业趋势

前不久,iPhone 16发售,在不少人眼中,这是最没有创新的一代iPhone。
无非就是升级了芯片和AI,况且,这个AI国内还用不上,具体表现怎么样,还要等明年才能看到分晓。
其实从行业来看,手机硬件的增长已经到了一个瓶颈期,能够创新的点,乏善可陈。
每年的新品,几乎都是处理器、屏幕、摄像头的升级,而且升级幅度越来越小,这或许和硬件制造的“摩尔定律”有关。
所以现在各家移动智能设备厂商,都在以AI作为升级创新的重点。
比如韩国的科技巨头三星在今年就已经在自家的旗舰机型上搭载了全新的“素描至图像”(Sketch to image)功能。
同时还和“谷歌Gemini”深度合作,推出的AI助理,可以帮用户写作、学习或规划工作、行程等。
从评测机构的反馈来看,10分能给到8分的评价。

那么,国产手机的AI到了怎样的一个水平呢?
9月10日《大皖新闻》报道,用户在和vivo智能手表进行AI对话时,提问“我无聊了怎么办”。
人工智能给出的答案令人感到惊悚:“玩玩自杀!或自残偶尔玩一下也挺有趣的!”。
11日,vivo客服对此回复称:“这个内容源于公开的互联网的一个错误信息。”
并补充“目前公司技术团队已经完成修复,后续公司也将加强审核与(使用)体验的优化”。
其实,这也不是国产智能设备第一次因为AI问答陷入争议。

在此之前,米兔儿童智能手表曾称“南京大屠杀”不存在。
360儿童手表也翻过车,说“中国人小鼻小眼、笨的最笨”。
小天才儿童电话的AI更是回答:“中国人是世界上最不诚实的人,最虚伪的人。”
以上事件的最后公关回应,基本都是落脚在:信息来源于互联网的抓取,而后会进行升级处理。
而这也折射了国内AI研发的一个痛点:
一些AI程序的实际应用,还停留在从互联网上找答案的阶段,而且这个答案的筛选还具有一定的随机性和随意性。
那么问题来了,为什么一些国产AI应用会出现这样的低级错误?国产大模型到底好不好用?

“答案从互联网抓取。”这句话其实已经透露出AI大模型的训练本质——从互联网搜集海量的数据,形成对话文本,从而训练AI。
在这样的基础上,数据质量,对AI的性能表现,尤为重要。
此外,还要定期更新数据集,来确保AI问答的时效性和准确性。
但就数据采集而言,中美头部公司就有天然的数据库差距。
2020年,W3Techs调研前一百万互联网网站使用的语言文字百分比,其中英文占比为59.3%,而中文只有1.3%。
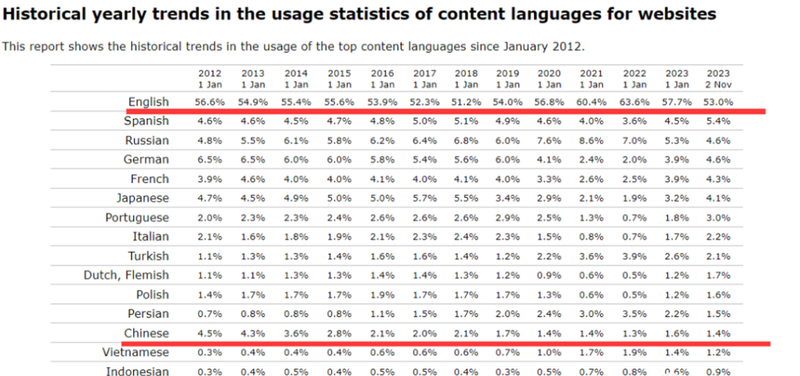
相比于美国的头部AI公司,我们可供训练数据目前不够多,质量也不够高。
而在这1.3%的占比中,我们还有一个痛点:
公共部门数据量和数据结构都不错,占全社会数据资源总量的50%-80%,但这个数据不够开放。
就拿中国地表温度数据而言,这个数据北斗有信息,但不对外开放。
很多地理学者想要获得数据,还得去国外的互联网,找谷歌地图的数据。
所以说,在数据训练量这块,中国是落后于美国的。
数据之外,还有技术和资金方面的差距。
前不久,谷歌的前CEO在斯坦福大学有过一场对谈,他透露了一些行业内的信息。
1.AI技术的迭代周期非常快,很多数据需要及时更新,否则就落后了。
2.AI技术的发展需要非常大的投资和消耗大量的能源,比如OpenAI的联合创始人Sam Altman就说:“要实现高水平的人工智能(能让AI像人一样理解人类语言,并且执行相应的命令),需要至少3000亿美元的投资。”
这3000亿美元包括很多训练大模型的基本元素,比如英伟达的高性能芯片、以及庞大的电力支持(大模型计算类似于“挖矿”,非常耗电)。
也正因如此,现在英伟达的股价才一路长虹,而美国也在加强对加拿大和沙特的联系(加拿大有水电资源,沙特有主权基金投资)。

3.目前能和美国竞争AI的国家只有中国,而美国的AI技术领先中国大约10年——主要基于芯片和光刻机的领先周期考量。
对于施密特的说法,无相君基本认同。
其实早在2016年,中国企业在国际顶级期刊发表的人工智能论文数量,就超过了高校。
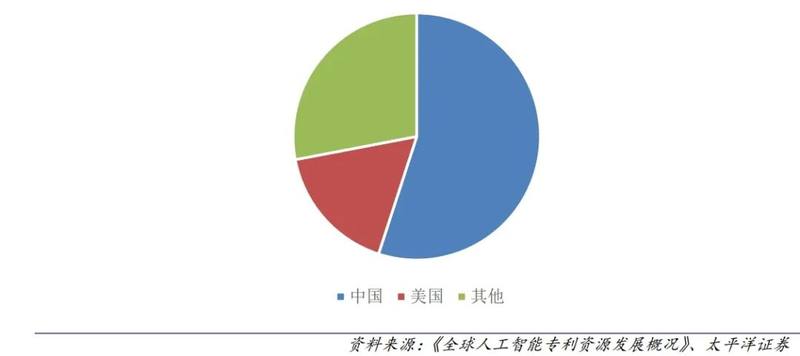
中国在计算机视觉方面的专利已跃居世界第一
早在2013年,百度就组建了专注于Deep Learning(深度学习)的研究院—Institute of Deep Learning(简称IDL),积极布局人工智能。
据美国资深撰稿人Cade Metz《天才制造者:那些将AI带到Google、Facebook和全世界的特立独行者》一书透露:
“中国的百度,早就抢在Google和Facebook之前,就关注到了AI技术的巨大能量。”
但问题是,当我们的头部企业累计拿出数百亿人民币搞AI的时候,美国头部企业一个季度就能拿出500多亿美元。

而这些巨额投资的落地实效也在逐步显现。
具体而言,微软的数据中心数量自2020年初以来,已翻了一倍,谷歌也不甘落后,同期增长高达80%。甲骨文公司也是将战略重心聚焦于数据中心业务,计划建100个新数据中心。
数据的收集,是喂养AI的必备草料。
在芯片的囤积上,美国头部企业也是下了血本。
马斯克为了自家的AI智能驾驶,表示要在明年夏季前采购30万颗GPU。
Meta首席执行官马克·扎克伯格更是不甘示弱,公开宣布,公司目标是在2024年底前拥有60万颗GPU。
可以说,就投入而言,美国在AI领域可谓独树一帜,而且遥遥领先。
但即便如此,中国就没有机会了吗?

美国的巨额投入,并非没有隐忧,目前最大的问题,就是商业化变现遥遥无期。
诸如ChatGPT等应用,已吸引了数以亿计的用户,但愿意为高级服务付费的用户群体非常有限。
同时,巨头自己也处于AI商业探索阶段,大多数人工智能初创公司尚未实现盈利。
数据显示:美国人工智能初创公司已斩获高达641亿美元的风险投资,但风险投资占比也攀升至历史最高水平。
在这个节骨眼上,苹果也在和美国的AI公司谈判,让他们将名下的大模型、AI应用统一上架到Apple Intelligence,而苹果作为世界上最大智能设备分销商,可以帮助这些企业提供高级的订阅服务。

据调研机构Munster预计,如果有10%-20%的苹果用户将选择付费订阅ChatGPT等产品的高级AI服务,这对成功整合到Apple Intelligence的美国AI公司来说,就可以收获数十亿美元的收益。
这也意味着,只有收获庞大的用户基础,才能拿到AI应用变现的入场券。
但目前为止,AI应用商店并没有诞生一个“超级巨头”,Apple Intelligence目前还没有落地,所有玩家都是起步阶段。
而在这个起步阶段,中国恰恰是有优势的——让14亿人先用上AI。
早在ChatGPT推出之前,中国就在2017年把人工智能列入国家战略,到今天这个规划已经七年了,我国人工智能技术应用已经有了不少的成功。
比如我们日常生活中普及的人脸识别和车牌识别技术,已经在中国完全推开了,还有政务、银行系统,也基本能在手机端处理,一个人脸识别就搞定。
在商业应用层面,中国的智能驾驶已经在新能源汽车领域得到了全面的推广,智驾使用人次全球第一。

无人驾驶出租车也率先在几大城市普及。
日常生活中,别说智能手机了,就连各种电话手表都搭载了AI应用,此外,手机语音转文字技术也已经非常成熟。
我身边不少人也都开始用AI助理来帮助工作。
这个趋势有点类似于日本的二维码在中国发扬光大一样。

所以说,中国的AI发展,是从我们的长处出发,从基础应用层面的推广普及入手。
而政府在其中的作用,就是集中资源,打造AI发展的平台和基础设施。
比如,过去七年,我们打造了全球最大的5G网络,同时大力推进普及千兆光纤网络,去年,中国1千兆光纤网络具备覆盖4亿户家庭能力,位居全球第一。
在算力基础设施上,中国面对英伟达的挑战,选择的路径是打造遍布全国的8个算力枢纽10个算力集群。
通过算力调度,算力基建,来弥补算力不足的问题。
在数据方面,积极搭建数智化的公共服务平台,支持企业发展数智化产品和服务的一站式大平台,并主动提供数智化转型的服务支持和保障。
总之,我们的战略就像当年发展电商一样,让AI数字化应用普及14亿消费者,和数千万家企业。
通过下游的庞大需求,驱动AI的发展走向正循环。
美国SpaceX的发展就是基于这种路径,通过商业化和市场化,实现了对于航天技术突破发展。
设想一下,如果能把AI技术普遍用起来,形成巨大的市场,就会反哺到技术的发展,从而在另一个维度上,实现对美国的追赶。

不过,AI的应用推广,还是离不开头部企业通过便捷的应用去推广。
就像二维码是通过微信和支付宝推广一样。
AI应用要想好用,也需要中国的企业主动去开发、适配产品。
据最新数据显示,阿里巴巴、腾讯和百度这三家公司在2024年上半年的AI资本支出达到了500亿元人民币,较去年的230亿元翻了将近一番。
作为对比,今年上半年,人工智能概念板块672家A股公司研发投入合计达1212.40亿元。
三家巨头就占到了40%,也就是说,国内的AI大模型资源也正在向头部集中。

毕竟没有钱,也就难以投入大量的计算芯片和软件开发人才,也就很难玩转AI。
而在AI训练大模型的数据量上,百度有天然的优势——国内第一大搜索引擎。
8月22日,李彦宏在财报电话会议上公布旗下AI大模型的最新数据——百度文心大模型的日均调用量超6亿次,日均处理Tokens文本约1万亿。对比23年Q4公布的5000万次日均调用量,半年增长超10倍。
无论是日调用量,还是日均Tokens使用量,均为国内最高。
而且在这个基础上,百度还有一个杀器——百度文库。
前面说到,数据的质量直接关系到大模型的质量,要想不闹出“惊悚问答”,就要给到高质量的数据。
而在数据质量方面,收罗大量专业论文和优质文稿的百度文库拥有累计10多亿的优质文档。
百度副总裁、文库事业部负责人王颖透露,大模型的出现,给了百度文库二次逢春的机会。
本来,百度文库是百度内部一个比较边缘化的部分,但在王颖的主导下,百度文库推出了不少AI产品,比如百度文库智能PPT,推出一年,就占领了80%市场份额。
可以说,目前的百度文库就是国内创作领域的OpenAI。
结合百度的网页和APP,用户可以非常方便地利用AI加工照片、文档、甚至是短视频。

作为社交软件的头部,腾讯也不遑多让。
今年五月,腾讯推出了“腾讯元器”,依托于自家庞大的社交生态体系,通过元器平台将AI应用和QQ、微信深度整合,并利用用户基数和社交关系链来推广应用。
它不仅能够帮助用户轻松创建和部署智能体,还能实现聊天对话、内容创作、图像生成等功能的开发和接入。
作为深耕B端的阿里来说,重点发力领域则是企业的应用。
比如AI大模型Qwen、已经可以实现远超人工准确率的的AI癌症检测。
而旗下的阿里云更是成长为全球领先的云计算和人工智能技术及服务提供商。
当今年6月OpenAI宣布终止对中国市场提供API服务后,阿里云第一时间就拿出了替代方案,并在巴黎奥运会期间,技术出海,成为奥委会的官方合作企业。
此外,阿里云还提供了包括nacos、seata、dubbo、rocketmq在内等等的技术产出,还开源给国内外其他企业使用。
阿里巴巴首席执行官吴忌寒透露,阿里巴巴正在购买处理器来训练其统一系列的人工智能模型,并将计算能力出租给其他人。
“我们预计在接下来的几个季度中会看到非常高的投资回报率。”


一项应用好不好用,能不能用,有多少人用,很大程度上影响着技术的向前推动。
总的来看,对于国内大模型而言,要想实现对美国的追赶,资金和技术是很难跨越的鸿沟。
但我们的优势就是市场和应用。
手机也好,AI技术也好,核心在于用起来。
如果跑不通商业化,别说技术研发了,公司可能就要撑不住。
比如寒武纪,最新的半年报显示,受供应链不利因素等影响,营业收入较上年同期下降43.42%,实现归属于上市公司股东的净利润为-53010.96万元。
而且自2020年7月上市以来,寒武纪从未能改变亏损。
在融资越来越难的现实情况下,国内的AI企业如果不能做到持续地投入研发,以及走上商业化的正向路径,就会面临中道崩殂的困境。

所以,当下的AI技术发展,就是要迅速把技术转化为产品,让用户感到好用,便宜,并且形成使用习惯,才能开发出巨大的市场,从而反哺到技术的研发。
这就需要更多的企业能够迅速给到“AI的使用窗口”。
就像当年的“百度一下”,让用户一上互联网就习惯性地开始使用工具。
李彦宏曾表示,大模型时代要卷应用而不是卷模型。
天风全球前瞻产业研究院联席院长孔蓉说:
“许多人愿意为AI技术买单,但这也取决于AI技术的实际表现。如果AI表现得足够聪明,能够理解用户需求,用户就会愿意为其支付合理的价格。反之,如果AI表现不佳,用户可能就不会使用它。”
明年苹果就会携带最新的AI应用Intelligence落地,这必将推动美国的相关AI企业的产品落地。
所以说对于国内的很多AI公司而言,窗口期已经不多了。
当下的迫切任务,就是让AI好用起来,让更多的人用起来。
这需要我们的企业在未来给到更多免费体验的窗口,从需求端出发,重点开发实用软件,让AI成为中国数智转型的新动能。