
图片来源:视觉中国
北京时间2月16日凌晨,没有任何预告,全球明星AI创业公司OpenAI发布了文生视频模型Sora,首次由AI生成了长达1分钟的多镜头长视频,其对于真实人类世界的高模拟度画面、精细的画质、多镜头拍摄、多角度运镜,表明AI对人类世界的理解、AI生成的创造性内容又上了新台阶。
多方评论认为,科技界与影视界或将迎来新一轮革命。
OpenAI首席执行官Sam Altman顺势在社交平台X上开始招聘:“OpenAI是我在一个地方见过的最有才华、最友善的一群人,致力于解决最困难、最有趣和最重要的问题,所有关键资源均已到位,非常专注于打造 AGI(通用人工智能),你也许应该考虑加入我们。”
而OpenAI的消息还不止于此。2月17日,据《纽约时报》和彭博社等媒体报道,OpenAI已完成一项允许员工出售公司股份的最新交易,使得这家AI明星公司的估值达到了860亿美元。
对电影行业的影响只是时间问题
远隔重洋,中国影视从业者也感到了巨大冲击。一位青年导演在2月16日发朋友圈说:“今日,大家正为AI的进步会在不远的将来抢走饭碗而倍感惶恐。”

Sora生成的视频中,主角脸上的雀斑清晰可见。图片来源:OpenAI官网
中国香港青年导演朱智立告诉蓝鲸财经记者,“它(Sora)对电影行业的影响只是一个时间问题,因为它已经把画面做到非常真实、有细节,包括一个女人在东京街头的画面,连脸上的雀斑都能做到非常真实。”
朱智立向蓝鲸财经表示,Sora对宣传片、广告片的影响会更大,“电影还有剧本、情节、台词等复杂因素,而在广告、宣传片行业,冲击可能会更快到来。如果提示词可以细节到分镜,那AI不仅仅是帮助导演画分镜和视觉参考图了,而是直接可以做成更高效的动态分镜预览,或者等技术更成熟时可以直接用来做成影视作品。”
虽然朱智立仍能在Sora生成的视频中发现一些bug(问题),但他认为修复这些bug只是时间问题,“有个视频是一个老奶奶吹蜡烛,但是蜡烛没有熄灭,意味着在情节的因果关系上有些bug。但几个月前Pika(另一家AI视频生成创业公司)才只能生成几秒钟的视频,当时我申请Pika账户,现在还没申请下来,几个月后Sora就出来了,能生成一分钟的视频。这些bug修复、技术迭代只是时间问题,可能比我们想得还要早。”
目前在影视界,特别是动画电影中,用文生图模型Midjourney来画前期动态分镜预览已很广泛。Previz(Previsualization,动态预览)是指在正式拍摄之前将拍摄内容简单制作一遍,用简单动画展示出演员走位、取景、摄影机角度与运动大方向,这原本是要一笔不小的预算和时间的,但AI可以低成本快速产出。
目前,朱智立正在筹拍的新电影就使用了Midjourney画分镜,对一些电影场景如七八十年代的香港码头、上海理发店的还原度很高,放到了他的电影项目书里,作为重要场景的视觉参考,“比导演用嘴巴去讲、自己用手画分镜要好很多。”

朱智立用Midjourney生成的电影场景图。图片来源:受访者提供
据《财经十一人》报道,目前不少视频创作者在以周为单位学习AI软件,全流程用AI制作视频,甚至拿到品牌商单。动画导演、兔斯基作者王卯卯强迫自己每周学2-3个AI软件,在学习了4个月AI后,她动手用AI制作视频了,从开始有创作想法,到生成主视觉图、生成动画,再到剪辑、加字幕,一个30秒的预告片只用了3个小时。
据报道,小红书博主@吴志气已经用AI制作多条商业广告,已经有品牌在接触AI视频创作者。他收到的最高报价是8000元/秒,听过的最高报价达到了10000元/秒。不过目前报价的底线也可以很低,有的只有500元/秒。
虽然很多影视、广告从业者感到了被AI抢饭碗的危机,但360公司创始人周鸿祎则发文表示:“今天很多人谈到Sora对影视工业的打击,我倒不觉得是这样,因为机器能生产一个好视频,但视频的主题、脚本和分镜头策划、台词的配合,都需要人的创意,至少需要人给提示词。一个视频或者电影是由无数个60秒组成的。今天 Sora 可能给广告业、电影预告片、短视频行业带来巨大的颠覆,但它不一定那么快击败TikTok,更可能成为 TikTok的创作工具。”
也有些内容生产领域对AI持审慎态度。刘先生目前在北京一家电视台担任视觉创意设计师,他在工作中不会用到AI,一方面是不能使用VPN,一方面单位会顾虑存在黑客盗取AI数据库的风险,“任何事情要首先考虑安全。”
力大砖飞的技术
Sora可以生成长达60秒的视频,此前文生视频时长最长的是另一家人工智能公司Runway,支持最多18s视频生成,镜头相对固定。由中国上市公司之女创立、曾引起A股轰动的Pika,此前生成视频长度在3秒左右,是单镜头,与其说是视频,更像是动图。
而OpenAI此次发布的Sora生成的视频有丝滑的移动运镜、场景转换,还可以自行分镜、切换景别,这意味着Sora可能让普通人以极低的门槛制作自己的电影。
另外,此前的文生视频模型,由于是生成单镜头,一旦输入新提示词,就会生成新镜头,主角就会变换,在实际的视频创作中有困难。而Sora生成的视频,在视角转换、镜头景别切换后,仍保持主体的一致性。
OpenAI官网介绍,“Sora能够生成具有多个角色、特定类型的运动以及主体和背景的准确细节的复杂场景。该模型不仅了解用户在提示中提出的要求,还了解这些东西在物理世界中的存在方式。”这意味着,如果说GPT能通过人类的语言来理解世界,那么Sora则能通过视频、图片等多模态数据来理解世界。
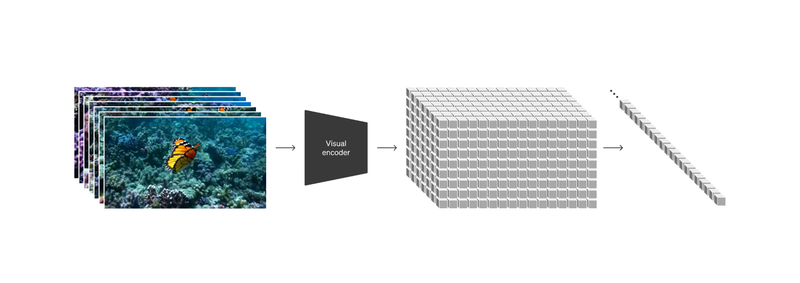
Sora模型的patches示意图。图片来源:OpenAI
Sora把视频和图像分解为较小的数据单元——“patches(小块)”,每个“patches”相当于GPT中的一个token(语句),这种编码十分灵活,通过patches来训练Sora模型。Sora使用了Diffusion扩散模型,它最初生成的视频看起来像静态噪声的视频,然后通过一步步消除噪声,来转换成清晰视频。据知危报道,相比于GAN生成对抗网络,Diffusion扩散模型像是一个勤奋且聪明的画家,并不是机械的仿作,在学习大量先作的时候,学会了图像内涵与图像之间的关系。
根据OpenAI的技术报告,Sora的强大得益于足量的数据、灵活的编码、优质的标注和Transformer+diffusion的架构。
据互联网程序编程算法领域博主宋博宁分析,以往此类模型对视频的处理往往会分解为时间域和空间域,用处理时间域的模型处理时间域,比如RNN、自回归模型等。但从报告来看,这次OpenAI直接把整个视频看做一个整体,一次性输入到diffusion模型中,让模型一次性生成出整个视频的每个细节。这样需要对视频进行压缩,但一次输入的数据量仍远远超过目前大模型支持的上下文长度。训练这样一个Diffusion Transformer模型需要巨大的计算成本。
既然训练模型这么烧钱,而芯片又是AI成本的大头,一直狂飙猛进的OpenAI也试图下场布局芯片了。不久前,据华尔街日报2月8号报道,Sam Altman正在与包括阿联酋在内的投资者进行谈判,以筹集数万亿美元资金,旨在提高全球芯片制造能力。其中一位知情人士表示,该项目可能需要筹集多达5万至7万亿美元的资金。据华盛顿邮报1月底报道,Sam Altman与美国国会议员讨论芯片制造业务,或与台积电等芯片制造公司合作。
芯片巨头英伟达在2024年开年短短一个半月时间,股价已经上涨46.63%,近一年更是上涨351.76%。截至2月16日,英伟达总市值接近1.8万亿美元,超过亚马逊和谷歌,仅次于微软、苹果和沙特阿美,为全球市值第四大公司。