
投稿来源:鹿鸣财经
人类语言相通的意义,可能远超你我的想象。
圣经旧约故事里,人类为了挑战上帝的权威想要修建一座能够通天的塔。上帝听闻决定惩罚人类,他悄悄来到人间改变并区分了人类的语言。渐渐地,使用不同语言的人们产生了隔阂,隔阂使人类不再强大,建塔的工程也就荒废了。
两千多年过去了,人类再次于尖塔下聚集,凭借着人工智能的力量再度向上帝发起挑战。
01
用算法模拟人脑
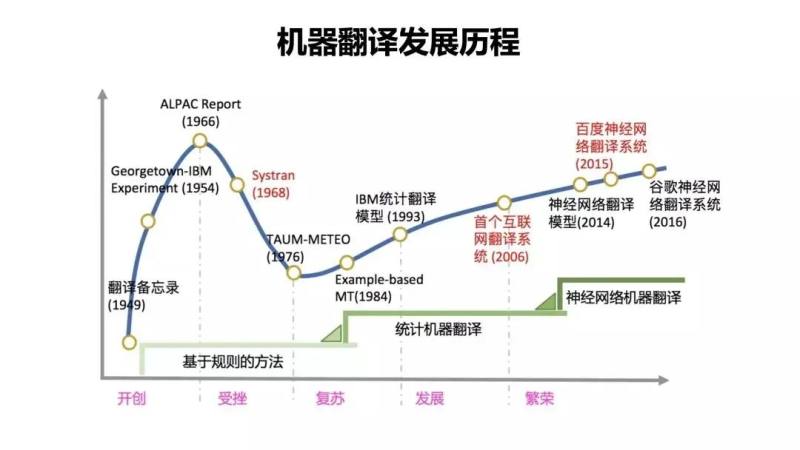
2014年,约书亚·本吉奥(深度学习三大神)一纸关于机器翻译的论文奠定了深度学习技术用于机器翻译的基本架构。如今,伴随着语音识别、人机交互、边缘计算等配套技术的发展,研究了近70年的智能翻译技术终于得以在旅游、会议、教学等各种生活场景之中崭露头角。
早在20世纪30年代初,法国科学家G·B阿尔楚尼就提出了用机器来进行翻译的想法。1933年,前苏联科学家特罗扬斯基提出了机器翻译的详细步骤,并以此设计出由一条传送带和台板依靠机械原理进行翻译的样机。
1946年,世界上第一台现代电子计算机诞生,而中国人形象地将其称之为“电脑”。用计算机代替人脑,这的确是个浪漫又不切实际的想法。
就在ENIAC问世的第二年,信息论先驱、美国科学家韦弗·华伦提出了利用计算机进行语言翻译的设想,在他发表的《翻译备忘录》中,基于电子计算机的机器翻译的概念被正式提出。
如何让计算机像人脑一样思考?这从来就是一个令人着迷的话题。思维如野马脱缰,一套基于规则的研究理论在学界被迅速建立。1954年,美国乔治敦大学与IBM合作,利用IBM-701 计算机首次完成了英俄机器翻译试验,它向科学界展示了机器翻译的可行性,就此拉开了机器翻译的研究序幕。
可0和1究竟要如何理解人类的语言呢?
彼时,机器翻译主要靠的还是语言学家亲自为系统制定规则。
例如我们定义:当“一个人”三字连续出现时它将被整体翻译为“a man”,而当只有“个人”二字连续出现时则应该翻译为“individuals”。
这种方法的准确率较高,但成本也高,且随着规则数量的不断增多,规则与规则之间开始互相影响与制约,定义规则的难度也不断上升。
例如定义了“individuals",那“single”又该如何定义呢?词汇与词汇的应用范畴总是相互叠加的,如果只是一味覆盖定义而非一一穷举,那整个系统势必会成为一条不断吞食自我的衔尾蛇。
实际上,语言的规则是几乎无法被精确还原的。它出之于人脑,而人脑却是一个充满混沌的黑盒。正如语言学里一个经典的提问:“人类究竟是否会产生无法用语言描述的思考?”
现代脑神经科学的研究表明,我们在我们脑中形成的任何一个念头都来自于大脑记忆与生理信号以及外部信息的深度融合。
正如你我看到下图时的反应一样,它绝非是我们大脑产生的线性反射,而是基于多种因素的主观判断。
这种由大脑内部混沌所操纵的主观判断导致我们无论如何都无法构建一个完全拟真的电子大脑。
来自底层的障碍让人类重建巴别塔的野心一度跌落到了谷底,机器翻译的发展进程也随之回到了原点。
学术界的寂静一直持续了近20年,直到1993年《机器翻译的数学理论》的发表。它阐述了一套从根本上有别于基于规则的实现思路,致力于避开深居内部的混沌,对已经外化的混沌进行转化。
其彻底放弃为翻译系统构建预设的知识框架,转而尝试用结果生成结果。通过把海量的语料进行切分与归类,再依照一套简单逻辑进行调取与重组,实现对目标语言的拼接。
相较于定义规则,这更像是一种粗犷却行之有效的嫁接方案。上文提到的韦弗·华伦就提出过类似的概念,只不过那时并没有足够的平行语料(不同语言的同义表达文本)供其收录,又受制于计算机羸弱的处理能力,因此没能付诸实践。
如今,搭建基于此种思路的翻译系统已经显得毫无难度,它极大程度地降低了人工投入。在过去十多年里,大家所熟悉的谷歌翻译就是用统计的方法实现的。
基于统计,我们大体实现了对多语种的基础翻译。然而,这种大体实现仅仅是建立在理论上的,当落到实际体验上就时常变得不尽人意。面对两个只有一词之差的句子,一个翻得表情达意,一个却翻得狗屁不通都是常有之事。
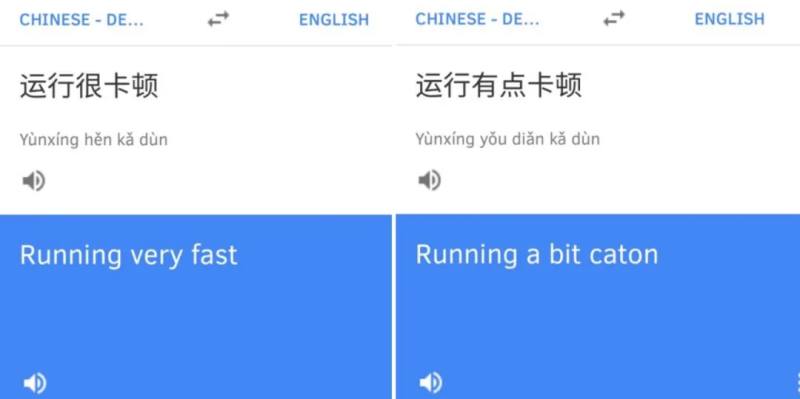
就比如要将“运行很卡顿”从汉语翻译成英语。如果语料中并没有“很卡顿”的案例,那么从左到右顺序调取统计结果,“运行很”接“快”字的录入信息是最多的,所以这句话被翻译成了“运行很快”,与原有的意思截然相反。
显然,这种基于统计的思路也并不可靠。实现对语料的拆分仅仅意味着理解了语句的成分,可单是凭借统计进行判断,依然不能摆脱“更像机器”的线性思维。
由此,阻碍机器翻译进步的一切问题都重新回到了“如何让机器像人脑一样思考”。机器翻译与人工智能终于迎来了交汇。
时间来到2006年,杰弗里·辛顿(深度学习三大神之首)改善了神经网络优化过于缓慢的致命缺点,基于神经网络与深度学习的机器翻译成为可能。
利用算法,人们为机器翻译系统构建了一个与人脑结构类似的神经网络。与人脑类似,这套系统同样具备了负责存储与负责处理的两个模块。
在存储模块中,词与词,词与句之间的大量关联信息被搭载进来,这些关联信息就好比字典里的词条,用其他词汇解释另一个词汇,便定义了这些信息的内涵。这些通过神经网络所习得的基本概念就像我们的记忆一样,能够被相关联的外部信息主动调取。
而调取这些信息的便是处理模块。在拿到一段源语言后,处理模块便开始调取存储模块中的概念。随后,将句中每个词汇的相关信息与这个词在句中的位置信息相结合,并通过一种压缩算法将这些词汇逐一转化为一系列的低维向量,完成基于大数据与上下文的预处理。
这种处理的过程就好比我们的人脑把自然语言转化成了电信号,它将词汇与语法中复杂而抽象的联系转化为了可供计算的具体值。
接下来才是真正的深度融合。
这些数值将会依次通过由各种功能函数构建的“神经元”(神经元就像阀门,具有激活与非激活两者状态),当计算结果符合“神经元”的阈值便形成通路,转化为更加高维的向量,反之则进行淘汰或循环,由此诠释了“深度融合”的过程。

由句子中不同词汇转化而成的低维向量构成了模拟人脑的外部信息,而从存储模块调取的词汇内涵便是记忆信息,这便一举打破传统的单线思维,输出结果也更具柔性。
排开情感与基因本能的因素,这套系统模拟了一颗简易的大脑。
凭借着算法模拟而成的神经网络,我们终于搭建起了连接内外混沌世界的桥梁,我们用大数据抽取外部混沌中的片段,再通过神经网络将这些片段转化为知识,最终根据需要向外部重新输出。
计算机第一次拥有了作为“电脑”的能力。
现在,以百度、阿里、谷歌、微软为代表的一众科技公司先后打造了属于自己的神经网络翻译系统,人类踏入了一个模拟人脑的时代。
02
技术攻坚
十九世纪德国诗人斯蒂芬·格奥尔在诗中写到:“词语破碎处,无物可存在”。
为了早日重现巴别塔,人类在学术研究上一直都秉承着透明共享的原则。
2017年,谷歌发表了一篇名为“Attention Is All You Need”的论文。这篇论文首次提出了,新模型中引入了一种注意力机制,基于更合理的处理规则为源语言词汇建立权重,优化处理结果。
在机器翻译的场景实验中,其翻译效果全面击败了原有模型,并利用编码端的并行计算特点大大缩短了编码端的响应时间。
此后,Transformer大行其道,国内外各个研究团队都在2017年以后相继建立了基于Tansformer模型的神经网络翻译系统。
机器翻译驶入了通向应用的快车道。
在国内,目前实质拥有机器翻译科研力量的单位可以分成两类:一类是国有研究机构,主要有中国科学院自动化研究所、计算技术研究所,清华大学、东北大学、苏州大学、哈尔滨工业大学、南京大学等;另一类是商业公司设立的研究机构或者研发团队,如微软亚洲研究院、百度、有道、腾讯、搜狗、阿里巴巴、网易等。
澳门大学科技学院副教授黄辉与大连理工大学计算机学院教授黄德根教授在2019年科大讯飞举办的全球开发者节上对目前机器翻译的研究前景作出了如下判断。

其认为现阶段的困难大致来自两个方面,一个是技术面临攻坚,一个是商业模式无法研究提供动力。
首先是技术方面。
以科大讯飞为例,其机器翻译团队负责人表示:“其团队当下的机器翻译系统已经能在中英互译领域达到98%~99%的正确率,基本实现了输出结果的‘信’与‘达’。”
然而,在我们的自然语言中还普遍存在着大量歧义、传统文化,以及亚文化现象。例如“南京市长江大桥”“青梅竹马”“我去年买了个表”,这都是系统无法判别的。
针对这些问题学界也给出了一些相应的解决方向。其中较为实用的方法是基于规则思路进行知识融合,对用于深度学习的语料数据进行词义泛化。
针对存储模块的“疑难概念”进行人工优化,这就好比再聪明的学生也需要老师的点拨一样。
另一种方法是借助多模态的策略,为翻译系统搭建更多用于特定信息分析的平行模块,再将不同维度的输出结果进行融合,最终作出最符合情理的判断。
我们可以把这种策略的适用范围拓展到语音交互的场景中加以理解。在科大讯飞的同声传译现场,如果有一个基于视觉分析模块能够捕捉到嘉宾身前的“开发者大会”字样,语音识别模块就能立刻将注意力集中到与会议有关的词汇当中,便不再会把嘉宾口中的“来宾”在其发音不准时识别为“老兵”。
在模拟人脑的时代里,机器翻译的技术进步已经由规则驱动转变为了借助机器学习的数据驱动。
而翻译系统中的机器学习就是用源语言与目标语言组成的双语语料对系统的处理过程加以约束,这就好比告诉了你“和”与“差”,让你求出“减除”,从而得到一组系列函数,而这组函数将会成为神经网络里新的“神经元”。
因此,学习越多的数据,系统就会越“聪明”。目前,多数语种的语料数据都是极其稀缺的,如何对有限的数据进行高效标注与加工,进一步提高数据的学习价值成为了一个新的难题。
面对人工标注付出的高额人力成本,学界提出了一种无监督学习的机制。形象的说就是让系统自主预习新的知识,用系统辅助人工进行数据标注,通过算法对源语言进行自动压缩,使这些数据在用于学习时更容易被约束,从而释放更大的数据价值。
除了数据本身的稀缺以外,供机器进行学习的物理算力也极为稀缺。机器学习时间长,成本高。
在通用的CPU处理架构出现明显乏力以后,更加适用于特定应用场景的GPU方案成为了人工智能领域的新宠。
2017年,阿里巴巴启动NASA计划,发布国内首个机器学习平台——PAI。它在完全兼容世界上所有主流深度学习开源框架的同时,还在底层提供了强大的云端异构计算(混合架构)资源,并在GPU方案上实现了灵活的多卡调度,进一步优化了底层的物理算力。
之后,阿里又尝试在PAI上开发支持分布式训练的机器翻译系统,并于3月底完成了第一个版本。在英俄电商翻译质量优化项目中,分布式系统大大提高了训练速度,使模型训练时间从20天缩短到了4天。
关于技术,我们面临的问题其实还有许多,而这些问题也不仅仅是机器翻译的问题。让机器学会翻译或许是人工智能实际面临的第一个综合性问题,在机器翻译领域的技术实践为人工智能的长远发展提供了养料。
03
价值的分水岭
时至今日,这座21世纪的巴别塔似乎已经初见雏形,但如何持续有力的推动这样一个庞大的工程才是更大的问题。
1992年,师从姚天顺教授的朱靖波开始接触基于规则的机器翻译方法研究,他可能是中国最早开始研究机器翻译的一批人之一。7年以后,博士毕业的他选择留校继续从事这项工作。随后,朱靖波辗转到香港城市大学学习,半年以后,又去到南加州大学ISI研究所做访问学者,并在前计算语言学协会主席Eduard Hovy教授的指导下从事一段时间知识工程和机器翻译的科研工作。
在ISI研究所工作期间,朱靖波深刻地意识到前沿技术不应该跟着商业热点跑。2007年,朱靖波回到国内,组建起了自己的团队,开始着手研制自己的机器翻译系统。
2009年,他带领团队第一次使用统计机器翻译技术参加国内规模最大、历史最长的机器翻译比赛—CWMT评测,取得了汉英新闻翻译系统第二名的成绩,仅以微弱的差距落后于微软亚洲研究院。
在这次评测大会上,朱靖波教授注意到,绝大多数参赛单位都在使用英国爱丁堡大学的Moses开源统计机器翻译系统做优化,但是系统并没有针对以中文为核心的翻译任务进行调优,造成许多参赛单位的比赛结果并不理想。这让踌躇满志的朱靖波决定开发一套自己的开源机器翻译系统,让全世界的科研人员都可以在东北大学的平台上开展研究。
为了鼓舞士气,朱靖波还给这个系统起了一个很有内涵的名字—NiuTrans,小牛翻译。朱靖波说:“NIU蕴含着东北大学(NEU)、新(new)和老黄牛精神(牛)三重含义,Trans是translation的缩写,两个部分合起来,表达了团队要发扬老黄牛的精神,勇于创新,积极进取,努力打造出最牛的机器翻译系统。
2012年,朱靖波用他从同学、朋友那里筹到的200万元,注册了一家名为沈阳雅译网络技术的公司。这其实已经是朱靖波围绕机器翻译领域的第三次创业了,前两次都以失败告终。
并不出乎意料,这笔钱在2014年下半年就已经见底。朱靖波一度萌生了“退回实验室继续埋头做研究”的想法。直到2015年,一通来自科大讯飞的电话让这只悬崖边上的小牛重获新生——科大讯飞承诺为朱靖波的公司注资500万元。终于,朱靖波带着这只倔强的“小牛”熬到了柳暗花明。2018年8月14日,科大讯飞云开放平台正式接入小牛翻译开放平台,双方开始展开深度合作。
朱靖波说:“在未来的机器翻译领域只会存在两种企业,一种是小牛翻译,另一种是其他企业。”其实,朱靖波想表达的是小牛专心负责基础设施的研究与开源,而其他企业则利用小牛的平台进行各种应用领域的开发,在供应端内部营造一个良性发展的互利生态。
到今天,小牛翻译的合作对象已经拓展到了与包括华为、腾讯、科大讯飞、小米、京东、金山,中国联通在内的科技通讯企业,以及国家专利信息中心、网监、军队等政府部门。可以说,小牛翻译如今正朝着朱靖波自己所想的方向发展。
但在这看似光明的前景背后,从朱靖波的话语里我们依然能够感受到他的一丝忧虑。
“机器翻译在短期内不会迎来爆发,或许将来也不会。技术的发展是一个长期的过程,在一项研究没有表现出明显的变现能力之前,企业不会举重金支持。”换句话说,机器翻译在商业上的最大挑战不在内部,而在外部,即发展的长期动力一定是其所具备的市场价值。
这一点在腾讯的机器翻译战略上得到了很好的印证。从腾讯的AI研发团队AI Lab撰写的一篇稿件得知,其主攻方向正在由单一的机器翻译转向人机耦合的应用场景,致力于研发一人机交互式机器翻译应用。腾讯希望用最切合用户需求的方式迅速提高机器翻译的市场价值。
在国内,与许多特立独行的小团队一样做着长远打算的还有百度。
早在2010年,百度就开始整合AI研发资源;2013年建立“深度学习研究院”;2016年斥巨资研发的DuerOS(智能家居)与Apollo(智能汽车)两大平台相继推出;2017年在国内首届人工智能开发者大会上提出“All in AI”。
此后,百度在每个季度的财报中都会特意强调AI技术及应用的重要性,刚刚举行的百度世界2020大会也以“万物智能”为主题——然而资本市场仍是半信半疑,不肯轻易买账。
就拿百度飞桨实验室里的Paddle Quantum (量桨)来说,这是一款基于量子机器学习的工具集,支持量子神经网络的搭建与训练,是沟通人工智能与量子计算的桥梁。这在量子计算都还未成熟的今天来说根本就看不见多少商业价值。
但也正如朱靖波所言:“技术不能跟着热点走”,这些基础的研究皆是为未来铺路。
现如今,当下已有的人工智能技术都只能被叫作弱人工智能,即没有复杂推理能力,不能独立解决复杂问题。可一旦弱人工智能转变为强人工智能,则能带来接近无限的生产力,其商业价值也自然不可估量。
于我们而言,仰望高塔与追逐短期利益本就矛盾。我们价值观念的分水岭或许就是时代发展的分水岭。